
Introduzione
L’Istituto Poligrafico e Zecca dello Stato (IPZS), grazie alla sua storia di progettazione, sviluppo e realizzazione di prodotti di sicurezza e soluzioni tecnologiche integrate, gestisce, per conto dello Stato, la base dati normativa italiana, con l’archivio e il portale della Gazzetta Ufficiale e con il portale Normattiva.
Nel particolare contesto delle norme in multivigenza, vi è l’esigenza di tracciare tutte le fonti aggiornanti degli atti, tenere traccia del versionamento degli atti modificati e creare i link tra questi. Tali operazioni sono eseguite da una redazione di esperti di settore, in grado di ricostruire l’alberatura normativa a partire da un particolare atto, a beneficio della chiarezza e della consultazione normativa.

La banca dati di Normattiva contiene tutti gli atti normativi pubblicati sulla Serie Generale, aggiornati, in multivigenza, per un totale di oltre 200.000 documenti. Viene consultata quotidianamente da circa 50.000 utenti, tra questi vi sono cittadini ma anche il legislatore, addetti ai lavori ed esperti del settore.
In questo scenario, è nata la necessità di avviare uno studio, in collaborazione con il Politecnico di Bari che ha permesso, grazie all’utilizzo di tecnologie quali Deep Learning, il Natural Language Processing, e altri strumenti software basati su Intelligenza Artificiale (IA), di creare un Knowledge Graph della banca dati normativa italiana, consultabile e navigabile, al fine di creare un potente strumento di consultazione migliorando la fruizione dei contenuti.
Lo studio: applicazioni di Intelligenza Artificiale in ambito normativo
Ma andiamo con ordine con alcune, necessarie, informazioni di contesto. Il processo di pubblicazione di una legge coinvolge il Ministero di Giustizia per lo svolgimento delle funzioni ad esso riservate, quali la pubblicazione degli atti normativi e non normativi della Gazzetta Ufficiale, e l’Istituto Poligrafico e Zecca dello Stato ne cura la stampa e la diffusione anche con strumenti digitali del giornale ufficiale dello Stato.
In particolare, nel corso del tempo, sono state introdotte diverse variazioni volte alla digitalizzazione del processo di pubblicazione. Anche se le tecnologie susseguitesi sono state diverse, ancora oggi esistono attività manuali che possono introdurre il rischio di errori e, soprattutto, di rilavorazioni.
Lo studio, che ha visto coinvolti per 3 anni IPZS e il Politecnico di Bari, e che è stato pubblicato in occasione del terzo Convegno Nazionale CINI sull’Intelligenza Artificiale ITAL-IA 2023, ha avuto i seguenti obiettivi:
- realizzazione di un sistema di classificazione assistito basato su Deep Learning, introducendo un algoritmo di multi-label text classification pensato per i testi normativi;
- creazione di un grafo RDF esplorabile e navigabile della banca dati normativa e attivazione di un endpoint SPARQL per le attività di interrogazione;
- realizzazione di uno strumento di ricerca basato sul Deep Learning e tecniche di NLP, per recuperare i paragrafi di una norma con elevata similarità semantica.
Le operazioni di ricerca e classificazione hanno sfruttato il potenziale trasformativo dell’Intelligenza Artificiale; nel seguito di questo articolo affronteremo invece gli aspetti tecnici che hanno consentito la realizzazione del grafo della banca dati normativa.
Il Knowledge Graph normativo, software e tecnologie utilizzate
Lo studio ha fatto uso di OpenLink Virtuoso, una piattaforma che combina standard open per l’accesso, l’integrazione e la gestione dei dati.
In particolare, questo consente la creazione e l’implementazione di Knowledge Graph utilizzando dati esistenti accessibili tramite API.
Nello specifico questa ricerca rappresenta una pipeline sperimentale che:
- estrae le informazioni relative a ogni norma;
- processa le informazioni per costruire un file Turtle che possa essere utilizzato per costruire gli indici di un grafo RDF in un triplestore su OpenLink Virtuoso.
Grazie all’utilizzo di SPARQL è stato possibile attivare uno strumento di dereferenziazione, LodView, che permette di visualizzare in modo sintetico le informazioni memorizzate riguardo ad una specifica norma.
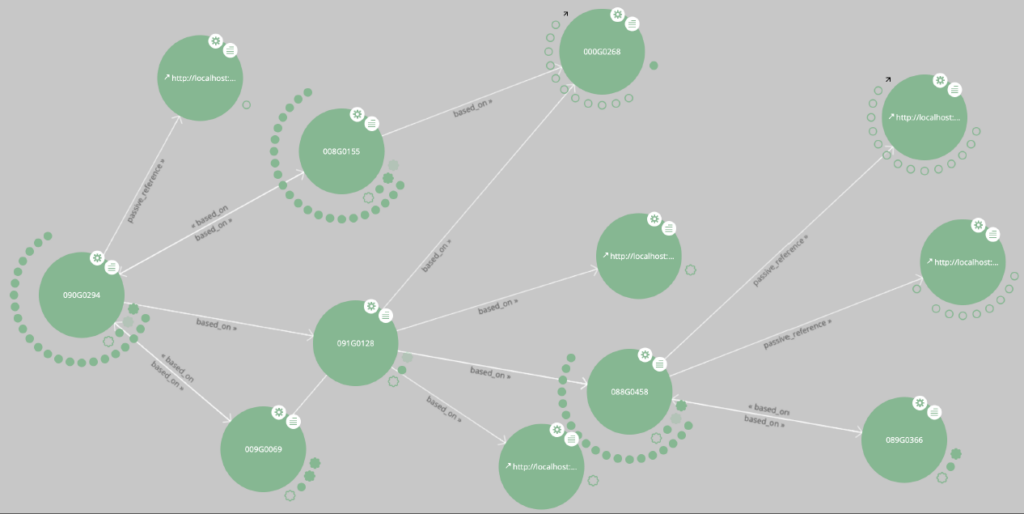
LodView, a sua volta, consente l’attivazione di un ulteriore servizio, LodLive, il quale, opportunamente configurato, consente di navigare in modo visuale il grafo normativo.
Descrizione della pipeline nel dettaglio
ll sistema per la rappresentazione, la visualizzazione e l’interrogazione del grafo delle leggi italiane offre molti vantaggi. Infatti, assiste gli operatori nell’individuazione dell’impatto normativo, innova e semplifica il gravoso compito legato ai processi decisionali degli operatori di settore ed offre un innovativo strumento di consultazione che agevola la fruizione dei contenuti.
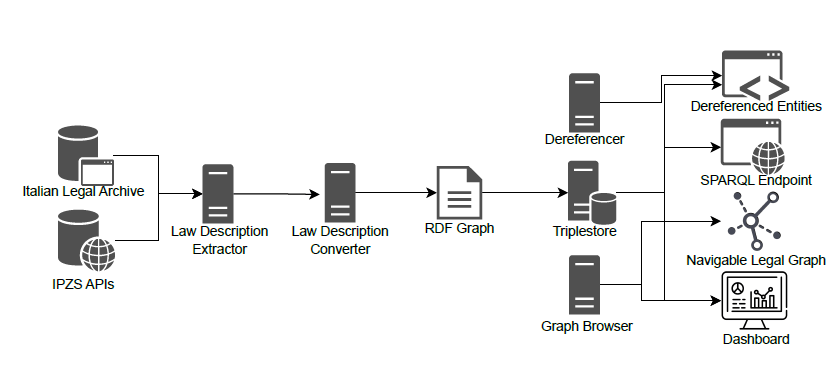
Di seguito vengono descritti gli elementi di cui si compone la pipeline.
Law description extractor module
Questo modulo carica l’intero database normativo a disposizione di IPZS.
Nonostante l’attuale archiviazione delle norme, il modulo permette di recuperare le informazioni da remoto tramite API ed è attualmente in grado di leggere e caricare il testo di ogni norma e di tutti i metadati.
In particolare, legge le norme e i suoi descrittori, raccoglie le norme in una struttura dati adatta alla conversione in grafo e riconosce le norme attualmente in vigore.
Law Description Converter Module
Il modulo trasforma la struttura dati della norma in un file adatto per essere caricato in un triplestore. Attualmente, il formato utilizzato è il turtle.
ll Law Description Converter è previsto di una struttura modulare, in cui ogni fase di trasformazione può essere attivata e disattivata, se necessario.
La sua funzione è quella di costruire la struttura normativa in formato grafo, identifica prefissi e predicati attualmente in uso in Linked Open Data, componendo i descrittori delle norme e salvando i dati in un formato compatibile con la successiva rappresentazione semantica.
Triplestore Module
Il Triplestore carica i descrittori precedentemente prodotti in un sistema capace di costruire il grafo RDF.
Dopo aver caricato i file rappresentativi del grafo, identifica i sottografi e ne consente l’interrogazione e l’aggiornamento.
Dereferencer
Il derefencerer consente la pubblicazione dei dati nel formato RDF secondo gli standard W3C, seguendo la Linked Open Data Initiative e utilizzando un endpoint SPARQL, inoltre, garantisce una buona esperienza utente per la consultazione dei dati poiché fornisce l’accesso alle risorse RDF attraverso pagine web.
Graph Browser
Questo modulo consente la navigazione dei dati esposti nella forma richiesta da Linked Open Data. Per farlo, richiede l’interrogazione di un endpoint SPARQL.
A partire da un nodo all’interno del grafo, il Graph Browser permette di navigare tutte le relazioni a partire da esso, raggiungendo così tutte le entità connesse.
Questo modulo include le seguenti features:
- Visualizzazione dell’entità e dei suoi relativi predicati.
- Visualizzazione degli oggetti (informazioni sulla norma o su altre norme).
- Possibilità di proseguire la navigazione attraverso nuove norme incontrate.
SPARQL Endpoint
Questo modulo espone le funzionalità di interrogazione sul grafo utilizzando linguaggio SPARQL standard e fornisce un’interfaccia unificata per l’utilizzo delle stesse.
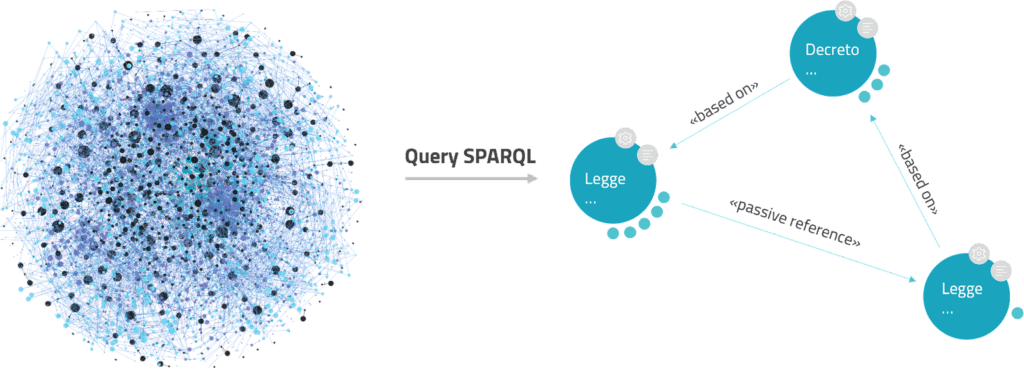
Questa architettura, quindi, consente di ottenere un Knowledge Graph derivato dalla banca dati normativa, interrogabile mediante query SPARQL (standard W3C), il cui risultato è consultabile in formato strutturato mediante LodView, e navigabile in formato visuale con LodLive. Inoltre, non viene richiesto agli utenti di conoscere SPARQL. Infatti, i meno esperti di questo linguaggio possono accedere ad interfacce grafiche che consentono loro di interrogare la banca dati in modo intuitivo.
Conclusioni
In conclusione, l’Istituto Poligrafico e Zecca dello Stato in collaborazione con il Politecnico di Bari, ha sviluppato una pipeline sperimentale per la creazione di un Knowledge Graph dell’intera banca dati degli atti normativi pubblicati sulla Serie Generale della Gazzetta Ufficiale.
Il progetto riduce il rischio di errori e incoerenze, introducendo l’automazione in un ambiente precedentemente basato su processi manuali, e rappresenta un passo importante verso l’innovazione delle tecniche utilizzate nel settore legislativo.
I risultati ottenuti hanno consentito la costruzione di un grafo RDF che semplifica la rappresentazione e l’esplorazione dei rapporti tra le diverse normative, da parte degli utenti.
Altri progetti
L’Istituto Poligrafico e Zecca dello Stato rappresenta una realtà industriale e tecnologica unica, complessa e in continua evoluzione: un’azienda poliedrica dal punto di vista dei prodotti e dei servizi che offre. Il Poligrafico realizza progetti mirati di ricerca e innovazione tecnologica, non solo in ambito digitale, e con l’utilizzo sempre più frequente di tecnologie di frontiera come, appunto, l’intelligenza artificiale.
Lo studio sull’uso di Applicazioni di AI in ambito normativo è frutto della collaborazione tra IPZS e il Politecnico di Bari, in particolare il SisInfLab, gruppo di ricerca impegnato attivamente nella ricerca di frontiera sui metodi di rappresentazione della conoscenza, sui Reccomender Systems e sulle applicazioni dell’IA in ambito medico, rendendo la ricerca di frontiera accessibile a tutti attraverso chatbot e la generazione di spiegazioni delle predizioni fornite.
La ricerca sull’uso di tecniche di AI in ambito normativo non è l’unica collaborazione in campo tra l’Istituto Poligrafico ed il Politecnico di Bari. Sono numerose le attività di ricerca intraprese e, tra queste, vi è lo sviluppo di materiali e processi di produzione innovativi nei settori della sicurezza e dell’anticontraffazione.
Per restare aggiornato sulle attività e i progetti di IPZS segui i canali social X, LinkedIn, Facebook e Instagram!
