
Se sei qui, probabilmente hai già un’idea di cosa sia Quarkus. Ma, in poche parole, immagina Java in modalità turbo: leggero, veloce, e pronto per i container! Ora, uniscilo a OpenShift, che è praticamente un parco giochi per applicazioni containerizzate, ed eccoti una combo che spacca.
In questa guida ti mostrerò non solo come fare il deploy su OpenShift della tua applicazione Quarkus (lo sappiamo, suona figo, vero?), ma si concentra su tecniche avanzate per ottimizzarla per l’ambiente OpenShift, garantendo performance, affidabilità e gestione efficiente. Non servono magie, ma solo un po’ di preparazione e voglia di sperimentare.

Prima di iniziare: i “superpoteri” necessari
Per seguire questa guida senza intoppi, assicurati di avere:
- una base su Quarkus e OpenShift. Non ti preoccupare, non serve essere un guru;
- un cluster OpenShift pronto all’uso (va benissimo anche la Developer Sandbox di Red Hat, gratuita e super easy).
- accesso alla CLI di OpenShift (oc), una JDK 21+, GraalVM 21+ (per la build nativa). Ah, e ovviamente un tool per i container come Docker o Podman;
- Apache Maven 3.9.9 (opzionale nel caso di uso del wrapper Maven integrato con il progetto di esempio);
- Quarkus CLI 3.17.
Riguardo il cluster OpenShift, faremo uso della Developer Sandbox di Red Hat. È un ambiente cloud preconfigurato e pronto all’uso che fornisce agli sviluppatori un’opportunità per esplorare, sperimentare e testare le tecnologie Red Hat senza dover configurare un’infrastruttura complessa, di conseguenza senza la necessità di installare o configurare nulla localmente sulle proprie macchine.
Per iniziare a utilizzare la Developer Sandbox di Red Hat, è sufficiente registrarsi gratuitamente al seguente link e installare la CLI di OpenShift necessaria per eseguire il login sul cluster OpenShift fornito dalla Developer Sandbox di Red Hat e opzionalmente per eseguire operazioni sul cluster.
Quelle poche operazioni necessarie sul cluster OpenShift le faremo usando esclusivamente la CLI di OpenShift e in particolare il comando oc. Ovviamente, per chi volesse utilizzare l’interfaccia grafica di OpenShift può farlo accedendo alla Developer Sandbox di Red Hat utilizzando il browser.
Per mettere in pratica ciò che sarà affrontato nel corso dell’articolo, faremo riferimento al progetto di esempio quarkus-graphql-quickstart pubblicato su GitHub; è pertanto necessario (o meglio preferibile) il tool git per eseguire il clone e un semplice editor di testo a vostro piacimento per le modifiche che apporteremo al progetto nel corso dell’articolo.
L’estensione OpenShift: Il Vostro Migliore Amico
L’estensione OpenShift di Quarkus è come un supereroe che semplifica la vita! Funziona come un “wrapper” dell’estensione Kubernetes, ma con impostazioni predefinite per OpenShift. Questa estensione è come il tuo compagno di squadra che fa il lavoro pesante: configura Kubernetes per te e crea tutto ciò che ti serve per far partire la tua app. Cosa fa di bello?
Costruzione di immagini container: il plugin OpenShift utilizza build binarie di OpenShift per creare immagini container all’interno del cluster OpenShift. Invece di usare Docker o Podman, l’artefatto e le sue dipendenze vengono caricati nel cluster e uniti a un’immagine builder (di default fabric8/s2i-java). Questo approccio permette di costruire immagini senza la necessità di un client Docker o di un daemon Docker in esecuzione.
Configurazione: l’estensione OpenShift aggiunge diverse opzioni di configurazione specifiche, come la strategia di build (quarkus.openshift.build-strategy), l’immagine base per le build JVM (quarkus.openshift.base-jvm-image) e native (quarkus.openshift.base-native-image), e la possibilità di specificare Dockerfile personalizzati (quarkus.openshift.jvm-dockerfile e quarkus.openshift.native-dockerfile).
Risorse OpenShift: l’estensione si occupa della creazione di oggetti BuildConfig e ImageStream necessari per le build OpenShift. Di default, la build è di tipo s2i binary, prendendo come input il jar creato localmente e producendo un ImageStream che avvia automaticamente un deployment
Deployment automatico: è possibile attivare build e deployment in un unico passaggio usando la proprietà quarkus.openshift.deploy=true. Per esporre automaticamente il servizio, è possibile impostare anche quarkus.openshift.route.expose a true.
Alternative non-S2I: è possibile usare anche altre estensioni per le immagini container come container-image-docker o container-image-jib. In questo caso, viene creato un ImageStream che punta a un dockerImageRepository esterno.
Customizzazione: oltre al deployment, è possibile personalizzare la creazione di risorse come Deployment, StatefulSet, Job o CronJob attraverso la proprietà quarkus.openshift.deployment-kind. Si può anche configurare l’esposizione di Route, variabili d’ambiente, volumi persistenti e altro.
Knative (OpenShift Serverless): per usare Knative, è necessario impostare quarkus.kubernetes.deployment-target=knative. L’estensione Quarkus può generare risorse Knative, e usare S2I per costruire l’immagine container nel cluster.
Client OpenShift: Quarkus fornisce anche le estensioni quarkus-kubernetes-client e quarkus-openshift-client che integrano il client Fabric8 per un accesso programmatico alle API di Kubernetes e OpenShift.
Da questa sintetica overview, è abbastanza chiara l’integrazione profonda con OpenShift di cui vedremo alcuni aspetti nel corso di questo articolo di approfondimento.
Il Progetto di Esempio: Quarkus GraphQL
Questo progetto è una dimostrazione di un’applicazione Quarkus che espone dati attraverso una API RESTful tradizionale e una API GraphQL. Il progetto utilizza Hibernate ORM con Panache per la persistenza dei dati e include configurazioni per database H2 (per sviluppo), PostgreSQL (per profili di produzione) e MinIO come Object Store S3.
Lo scopo di questo progetto è dimostrare:
- Integrazione di Quarkus con GraphQL: come esporre un’API GraphQL per interrogare e manipolare dati.
- Integrazione di Quarkus con JPA/Hibernate: come utilizzare Hibernate ORM con Panache per la persistenza dei dati.
- Esposizione di API RESTful: come creare API REST tradizionali per gli stessi dati.
- Utilizzo dell’estensione OpenShift: deploy su OpenShift dell’applicazione in ambiente K8s.
- Gestione di configurazioni multiple: come configurare diverse impostazioni per ambienti di sviluppo e produzione.
Il progetto segue la classica architettura a tre strati:
- Strato di Persistenza (ORM/Panache): utilizza Hibernate ORM con Panache per la gestione e la persistenza dei dati nel database.
- Strato di Servizio/API (GraphQL e REST): espone i dati attraverso API GraphQL e API REST, fornendo un’interfaccia per le interazioni.
- Strato di Presentazione (Opzionale): il progetto non include un livello di interfaccia utente dedicato.
Il diagramma mostrato a seguire evidenzia la stratificazione dell’applicazione.
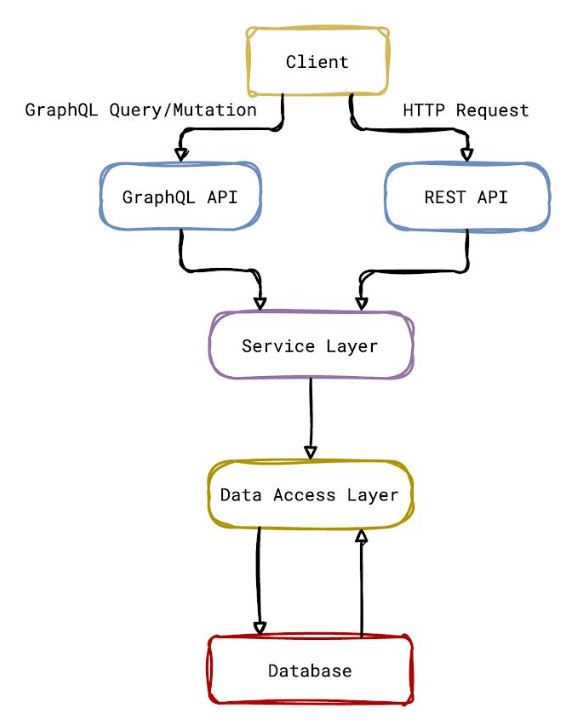
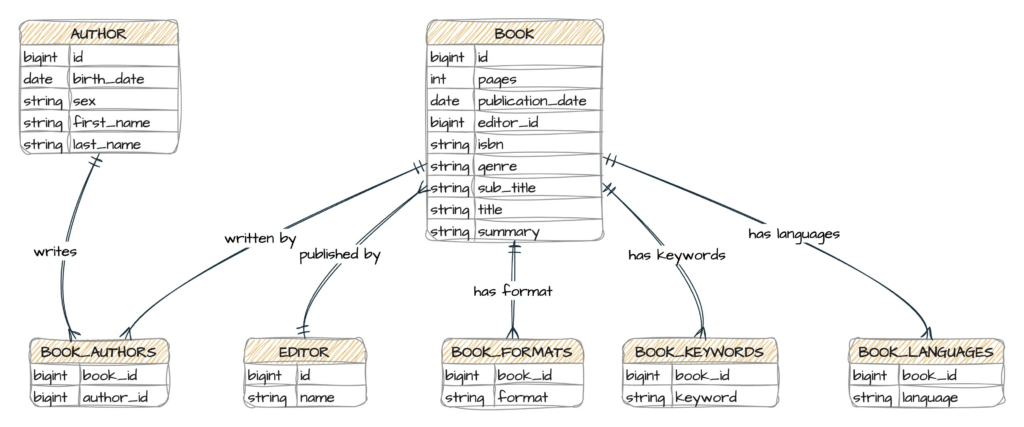
Per ogni livello dell’applicazione, vediamo quali sono i componenti principali partendo dalle entità JPA/Panache che sono:
- Author: rappresenta un autore di libri.
- Book: rappresenta un libro, con relazioni Many-to-Many con autori e Many-to-One con editori.
- Editor: rappresenta una casa editrice, in relazione One-to-Many con i libri.
Il diagramma mostrato a seguire evidenzia le entità sopra descritte e le relazioni.
Per il livello di Servizio/API, vediamo quali sono i componenti che implementano specificatamente le GraphQL API e REST API.
- BookGraphQL: classe che implementa le query e le mutation GraphQL per i libri e gli autori.
- allBooks: Query per recuperare tutti i libri.
- getBook: Query per recuperare un singolo libro per ID.
- createBook: Mutation per creare un nuovo libro.
- addAuthorsToBook: Mutation per aggiungere autori a un libro.
- allAuthors: Query per recuperare tutti gli autori.
- BookResource: endpoint REST per la gestione di risorse di libri.
- getAll: Recupera tutti i libri.
- create: Crea un nuovo libro.
- update: Aggiorna un libro esistente.
- delete: Elimina un libro.
- addAuthors: Aggiunge autori ad un libro.
- FileResources: endpoint REST per la gestione di risorse da memorizzare sull’Object Store S3. Le risorse potrebbero essere per esempio i file immagine che rappresentano le cover (front e back) dei libri.
A seguire è mostrato un macro deployment/component diagram dell’applicazione Quarkus quarkus-graphql-quickstart.
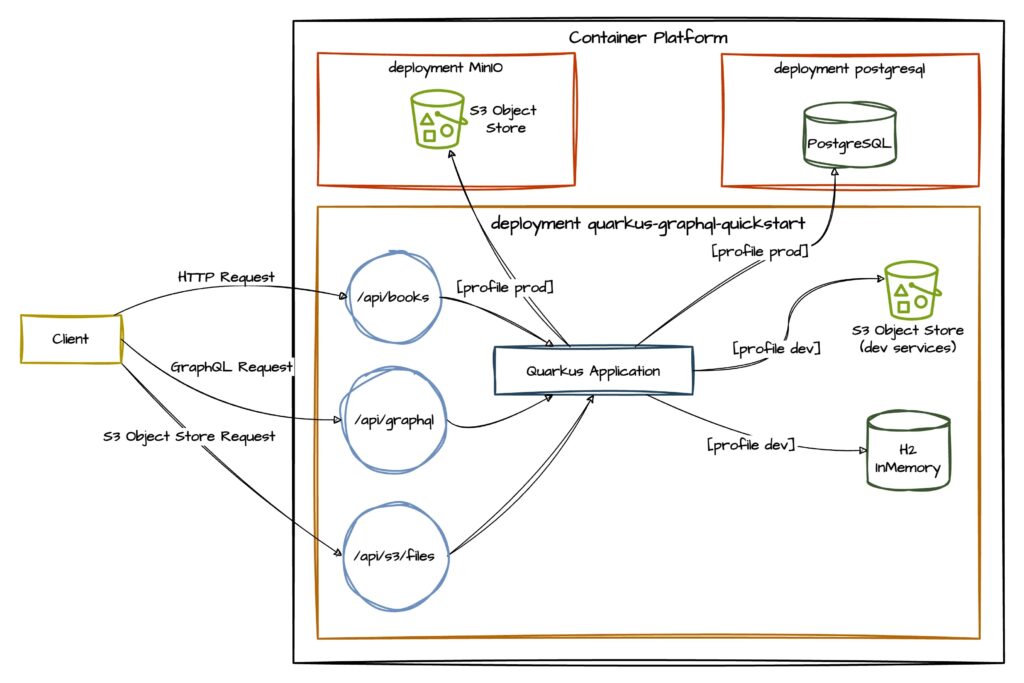
Se vuoi saperne di più sull’app della quale andremo a fare il deploy su OpenShift, dai un’occhiata al progetto su GitHub: quarkus-graphql-quickstart.
Come adeguare il progetto per OpenShift
Quarkus offre la possibilità di generare automaticamente risorse OpenShift in base a valori predefiniti e alla configurazione fornita dall’utente; per ottenere ciò, è necessario apportare alcune modifiche alla configurazione del progetto e in particolare:
- aggiungere la dipendenza
quarkus-openshiftal progetto; - aggiungere la dipendenza per le specifiche MicroProfile Health;
- configurare il plugin
quarkus-openshiftper generare le risorse OpenShift in modo adeguato.
L’estensione OpenShift è in realtà un’estensione wrapper che configura l’estensione Kubernetes con impostazioni predefinite in modo che sia più semplice per l’utente iniziare con Quarkus su OpenShift. Le impostazioni predefinite includono la generazione di risorse OpenShift come: Deployment, Service, Route, ConfigMap, Secret, PersistentVolumeClaim e BuildConfig.
Per aggiungere la dipendenza quarkus-openshift al progetto, puoi usare la CLI di Quarkus o Maven. Ecco i comandi per farlo con entrambi.
# Aggiungere la dipendenza per il deploy su OpenShift
# tramite la CLI di Quarkus
quarkus extension add quarkus-openshift
# Aggiungere la dipendenza per il deploy su OpenShift
# tramite il comando Maven
mvn quarkus:add-extension -Dextensions='quarkus-openshift'Code language: Bash (bash)La nostra applicazione deve essere accessibile fuori dal cluster OpenShift e per ottenere ciò, dobbiamo aggiungere la configurazione mostrata a seguire sul file di configurazione application.properties.
# If true, the service will be exposed outside of the cluster
# and will be assigned a route.
# If false, the service will only be accessible within the cluster (default)
# Environment variable: QUARKUS_OPENSHIFT_ROUTE_EXPOSE
quarkus.openshift.route.expose=true
Code language: Properties (properties)Di default, l’applicazione è esposta all’esterno via HTTP. Per usare HTTPS, basta configurare l’estensione quarkus-openshift con i dati del certificato e della chiave privata.
È utile avere un’idea chiara delle risorse OpenShift/Kubernetes coinvolte nel deploy. L’estensione quarkus-openshift genererà i file YAML relativi all’app. Ecco un diagramma che mostra tutte le risorse usate nel deploy su OpenShift.
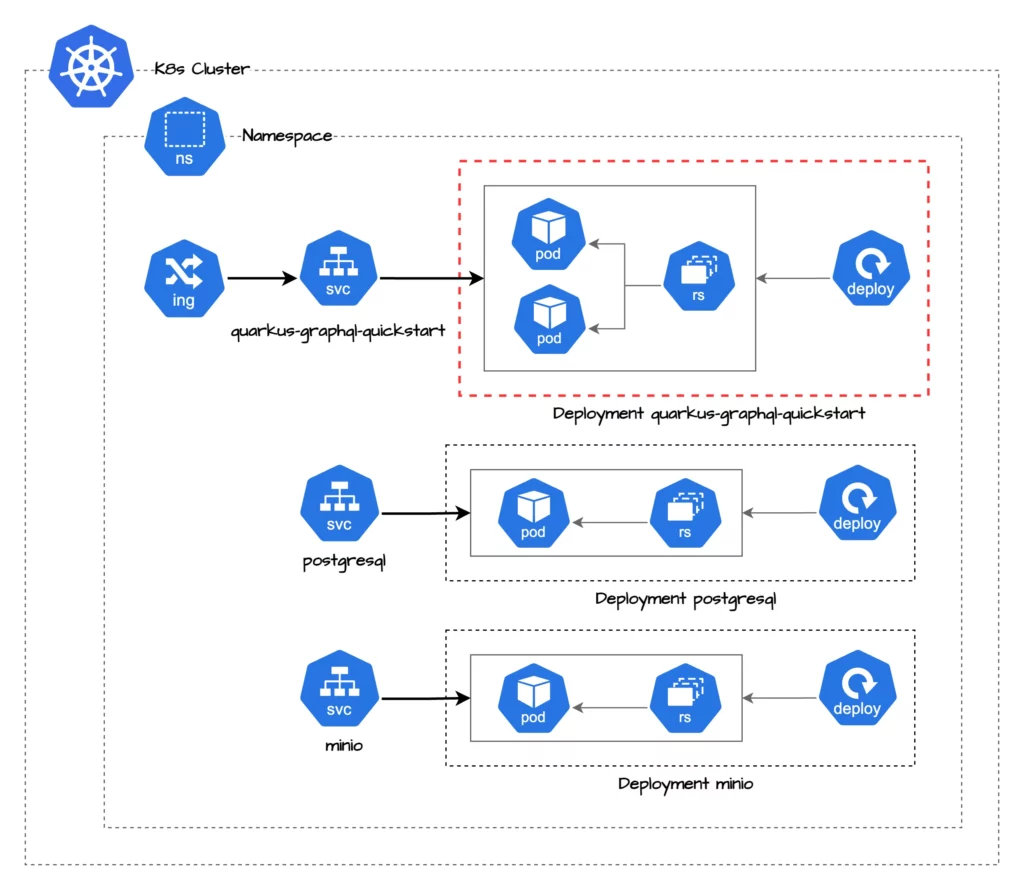
Il diagramma mostra un Deployment con il Pod (o i Pod) dell’applicazione Quarkus, un Service per esporlo all’interno del cluster e una Route per renderlo accessibile all’esterno. Sono inclusi anche i servizi esterni come il database PostgreSQL e MinIO Object Store, ma qui ci concentreremo solo sul deploy dell’applicazione.
In un cluster Kubernetes, i pod di ogni deployment comunicano tra loro tramite il Service. Questo è importante quando si configura un’applicazione Quarkus, soprattutto per le connessioni ai servizi esterni, come il database PostgreSQL e il servizio di Object Store (MinIO).
L’estensione quarkus-openshift genererà automaticamente le risorse OpenShift/Kubernetes in base alla configurazione fornita dall’utente e alle impostazioni predefinite.
Perché aggiungere il supporto per le specifiche MicroProfile Health?
L’estensione OpenShift di Quarkus usa MicroProfile Health per controllare lo stato dell’applicazione e verificare se è pronta a ricevere traffico. Questa estensione, fornita da SmallRye Health, è fondamentale per le probe di Liveness, Readiness e Startup Probe, concetti chiave per le applicazioni cloud native, soprattutto per l’orchestrazione e gestione dei container in Kubernetes. Ecco un’analisi dell’importanza di ciascuna probe.
- Liveness Probe: è un meccanismo per determinare se un’applicazione è in esecuzione e funzionante. Se l’applicazione non è in esecuzione, Kubernetes la riavvierà. Questo è utile per evitare che un’applicazione non funzionante riceva traffico.
- Readiness Probe: è un meccanismo per determinare se un’applicazione è pronta per ricevere il traffico. Se l’applicazione non è pronta, Kubernetes non invierà traffico all’applicazione. Questo è utile per evitare che un’applicazione non pronta riceva traffico.
- Startup Probe: è un meccanismo per determinare se un’applicazione è stata avviata correttamente. Se l’applicazione non è stata avviata correttamente, Kubernetes la riavvierà. Questo è utile per evitare che un’applicazione non avviata correttamente riceva traffico.
Per aggiungere la dipendenza MicroProfile Health al progetto, puoi usare la CLI di Quarkus o Maven. Ecco i comandi per farlo.
# Aggiungere la dipendenza per le specifiche MicroProfile Health
# tramite la CLI di Quarkus
quarkus extension add smallrye-health
# Aggiungere la dipendenza per le specifiche MicroProfile Health
# tramite il comando Maven
mvn quarkus:add-extension -Dextensions='smallrye-health'Code language: Bash (bash)Importando l’estensione smallrye-health, Quarkus crea automaticamente le probe di Liveness, Readiness e Started per l’applicazione. Queste probe servono al cluster OpenShift (o K8s) per verificare se l’applicazione è pronta a ricevere traffico. Al lancio dell’applicazione, saranno disponibili queste probe.
- Liveness:
/q/health/live– questa probe è utilizzata per determinare se l’applicazione è in esecuzione e funzionante. - Readiness:
/q/health/ready– questa probe è utilizzata per determinare se l’applicazione è pronta per ricevere il traffico e di conseguenza servire le richieste. - Started:
/q/health/started– questa probe è utilizzata per determinare se l’applicazione è stata avviata correttamente. - Health:
/q/health– questa probe è utilizzata per determinare lo stato generale dell’applicazione.
Aggiungere il supporto per il protocollo HTTPS
In questo scenario, garantiamo la sicurezza end-to-end tra il client e l’applicazione, senza affidarsi a dispositivi intermedi. In ambienti distribuiti, come nei microservizi, ciò assicura che le connessioni siano protette fino all’applicazione, non solo fino al gateway.
Ottenere il risultato sopra descritto, significa apportare alcune configurazioni al livello dell’applicazione e istruire l’estensione di OpenShift affinché crei le risorse per il cluster in modo adeguato.
Per l’applicazione e sufficiente indicare il keystore che conterrà la coppia di chiavi (privata e pubblica), il tipo, la password di accesso e la posizione.
Per le risorse del cluster OpenShift:
- esposizione dei servizi dell’applicazione fuori dal cluster attraverso una route;
- la target port della route, in questo caso https;
- il tipo di terminazione TLS per la route, in questo caso passthrough. Questa configurazione garantisce che la crittografia TLS/SSL sia gestita internamente dall’applicazione e che il proxy di OpenShift non tenti di decriptare o criptare il traffico;
- la policy da applicare per le connessioni non sicure alla route, in questo caso la policy che imposteremo sarà None. Questo valore indica che le connessioni non sicure sono consentite, e quindi qualsiasi richiesta HTTP che tenta di accedere alla route senza utilizzare HTTPS sarà rifiutata;
- configurazione del Secret Volume dedicato alla gestione del keystore dell’applicazione;
- configurazione dei nomi delle Secret che contengono le informazioni di accesso al database, all’object store e al keystore.
A seguire la configurazione del keystore da inserire sul file di configurazione dell’applicazione (application.properties) e che riguardano esclusivamente l’applicazione per gestire correttamente il protocollo HTTPS.
# Setting the key store file
# For default environment, the key store file is located in the resources folder
# For prod environment, the key store file is located in the /security/keystore folder
# mounted as a secret volume
quarkus.http.ssl.certificate.key-store-file=app-keystore.p12
%prod.quarkus.http.ssl.certificate.key-store-file=/security/keystore/app-keystore.p12
# Setting the key store password
# For default environment, the password is hardcoded
# For prod environment, the password is managed through a secret
# See the file src/main/kubernetes/common.yml where the secret is defined
quarkus.http.ssl.certificate.key-store-password=YXBwLWtleXN0b3JlLnAxMg==
%prod.quarkus.http.ssl.certificate.key-store-password=${APP_KEYSTORE_PASSWORD}
# Setting the key store type (PKCS12)
quarkus.http.ssl.certificate.key-store-file-type=PKCS12
Code language: Properties (properties)Il keystore si chiama app-keystore.p12 ed è in formato PKCS12. Sono stati usati profili per differenziare le configurazioni tra sviluppo e produzione. Di default, il file app-keystore.p12 è incluso nell’artefatto dell’applicazione e la password è predefinita. In produzione (profilo prod), il keystore è su un volume montato in /security/keystore/ e la password viene iniettata tramite un Secret.
A seguire la configurazione del keystore dal punto di vista delle risorse OpenShift che sono specifiche dell’estensione OpenShift.
# If true, the service will be exposed outside the cluster
# and will be assigned a route.
# If false, the service will only be accessible within the cluster (default)
quarkus.openshift.route.expose=true
# The target named port. If not provided, it will be deducted
# from the Service resource ports. Options are: "http" and "https".
quarkus.openshift.route.target-port=https
## Route TLS configuration:
# The termination type of the route. Options are: "edge",
# "reencrypt", and "passthrough".
quarkus.openshift.route.tls.termination=passthrough
# The desired behavior for insecure connections to a route.
quarkus.openshift.route.tls.insecure-edge-termination-policy=None
# Configure the secret volume for the application keystore
quarkus.openshift.secret-volumes."app-keystore-secret-volume".secret-name=app-keystore-secret
quarkus.openshift.secret-volumes."app-keystore-secret-volume".items."app-keystore.p12".path=app-keystore.p12
quarkus.openshift.secret-volumes."app-keystore-secret-volume".default-mode=0600
quarkus.openshift.mounts."app-keystore-secret-volume".path=/security/keystore
quarkus.openshift.mounts."app-keystore-secret-volume".read-only=true
# The name of the Secret that contains the database URL (that will be contained the username and password)
# and the application keystore password.
quarkus.openshift.env.secrets=db-username-password,db-url,minio-access-key,app-keystore-password
Code language: Properties (properties)Le configurazioni descritte permettono all’applicazione, eseguita in locale, di esporre gli endpoint HTTPS e fanno sì che l’estensione OpenShift generi correttamente i file yaml per il deploy delle risorse K8s, garantendo un deploy su OpenShift senza problemi sul cluster.
Configurazione dei Secret
Nel diagramma di deployment dell’applicazione Quarkus, quest’ultima necessita di accesso a risorse esterne già disponibili (ad esempio, nel cluster o altrove), e dobbiamo configurare i dati di accesso. Per farlo, useremo i Secret.
I Secret permettono di separare e gestire centralmente le informazioni di configurazione dell’applicazione, in particolare per gestire in modo sicuro dati sensibili come username e password.
Dobbiamo scrivere noi i descrittori YAML dei Secret, poiché l’estensione quarkus-openshift non li gestisce. Tuttavia, l’estensione li aggiungerà al file YAML finale di deploy dell’applicazione Quarkus, che si trova in target/kubernetes/openshift.yml.
Metteremo il file common.yml nella cartella src/main/kubernetes. Di seguito, il descrittore YAML dei Secret necessari per il corretto funzionamento dell’applicazione sul cluster OpenShift.
---
# Secret for the database username and password
kind: Secret
apiVersion: v1
metadata:
name: db-username-password
data:
db-password: cXVhcmt1cw==
db-username: cXVhcmt1cw==
type: Opaque
---
# Secret for the database URL
kind: Secret
apiVersion: v1
metadata:
name: db-url
data:
db-url: amRiYzpwb3N0Z3Jlc3FsOi8vcG9zdGdyZXNxbDo1NDMyL3F1YXJrdXNfZ3JhcGhxbA==
type: Opaque
---
# Secret for the keystore password
kind: Secret
apiVersion: v1
metadata:
name: app-keystore-password
data:
app-keystore-password: WVhCd0xXdGxlWE4wYjNKbExuQXhNZz09
type: Opaque
---
# Secret for the keystore password
kind: Secret
apiVersion: v1
metadata:
name: minio-access-key
data:
minio-user-access-key: bWluaW8tYWRtaW4=
minio-user-secret-key: bWluaW8tYWRtaW4=
type: Opaque
Code language: YAML (yaml)Al momento del deploy su OpenShift dell’applicazione sul cluster attraverso il plugin di Quarkus, le Secret sopra indicate saranno create all’interno del cluster.
Ecco le configurazioni per le due risorse esterne, database e S3 Object Store. I dati di accesso sono protetti dai Secret e saranno resi disponibili al container come variabili di ambiente durante l’esecuzione dell’applicazione.
# PostgreSQL configuration (production)
%prod.quarkus.datasource.db-kind=postgresql
%prod.quarkus.datasource.jdbc.url=${DB_URL}
%prod.quarkus.datasource.jdbc.max-size=20
%prod.quarkus.datasource.username=${DB_USERNAME}
%prod.quarkus.datasource.password=${DB_PASSWORD}
# ORM configuration (production)
%prod.quarkus.hibernate-orm.log.sql=false
# MinIO configuration
%prod.quarkus.minio.url=http://minio
%prod.quarkus.minio.port=9000
%prod.quarkus.minio.secure=false
%prod.quarkus.minio.access-key=${MINIO_USER_ACCESS_KEY}
%prod.quarkus.minio.secret-key=${MINIO_USER_SECRET_KEY}
Code language: Properties (properties)Queste configurazioni sono valide solo per il profilo prod. In ambiente di sviluppo (profilo dev), l’applicazione userà un database H2 in memoria e il DevServices di MinIO per l’Object Storage S3.
Configurazione delle base image
Per il deploy su un cluster OpenShift, useremo la strategia s2i binary per costruire le immagini container, scegliendo le immagini base per la build JAR (JVM) o per la build nativa.
Le due proprietà sono rispettivamente: quarkus.openshift.base-jvm-image e quarkus.openshift.base-native-image.
Per il progetto di esempio, è stata impostata solo la versione più recente della base image JVM, mentre la versione della base image nativa rimane quella di default.
# The base image to be used when a container image is being produced for the jar build.
# The value of this property is used to create an ImageStream for the builder image used in
# the Openshift build. When it references images already available in the internal Openshift
# registry, the corresponding streams are used instead. When the application is built against
# Java 21 or higher.
quarkus.openshift.base-jvm-image=registry.redhat.io/ubi9/openjdk-21:1.21-3.1736923862
# The base image to be used when a container image is being produced for the native build.
#quarkus.openshift.base-native-image=quay.io/quarkus/ubi-quarkus-native-binary-s2i:2.0
Code language: Properties (properties)Le immagini base possono essere anche esterne ai registry Red Hat ma devono comunque essere compatibili con il formato S2i.
Le immagini base vengono usate nel processo di build, che non solo crea l’immagine container, ma genera anche un BuildConfig in OpenShift, definendo il processo di build, e un ImageStream che punta alla nuova immagine.
Ecco alcuni estratti dall’output del processo di build, evidenziando i punti salienti.
...
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Starting (in-cluster) container image build for jar using: BINARY on server: https://api.rm2.thpm.p1.openshiftapps.com:6443/ in namespace:antonio-musarra-dev.
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Applied: Secret db-username-password
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Applied: Secret db-url
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Applied: Secret app-keystore-password
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Applied: Secret minio-access-key
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Applied: ImageStream openjdk-21
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Applied: ImageStream quarkus-graphql-quickstart
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Applied: BuildConfig quarkus-graphql-quickstart
...
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Trying to pull registry.redhat.io/ubi9/openjdk-21@sha256:84cf3593e0d9f180eab856f24456f2b76dbb05ab072cccec4fd0505862801d40...
....
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Pushing image image-registry.openshift-image-registry.svc:5000/antonio-musarra-dev/quarkus-graphql-quickstart:1.0.0-SNAPSHOT ...
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Writing manifest to image destination
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Successfully pushed image-registry.openshift-image-registry.svc:5000/antonio-musarra-dev/quarkus-graphql-quickstart@sha256:9ac064d89418567e5f80793826f72c51c118838aa72bb3d8d2d229cc254bfded
[INFO] [io.quarkus.container.image.openshift.deployment.OpenshiftProcessor] Push successful
[INFO] [io.quarkus.deployment.QuarkusAugmentor] Quarkus augmentation completed in 172792ms
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 03:04 min
[INFO] Finished at: 2025-01-25T15:18:46+01:00
[INFO] ------------------------------------------------------------------------
Code language: JavaScript (javascript)Ora che abbiamo trattato questo aspetto, possiamo procedere con il deploy su OpenShift della nostra applicazione Quarkus sul cluster.
Primo deploy su OpenShift
Il nostro cluster di riferimento è quello della Developer Sandbox di Red Hat. Per il primo deploy su OpenShift, dobbiamo effettuare il login sul cluster usando il comando oc login, con la sintassi mostrata di seguito.
# Login tramite username e password (richiesta dopo l'esecuzione del comando)
oc login -u myusername
# Login tramite token (via preferenziale)
oc login --token=<tuo-token> --server=<tuo-cluster>Code language: Bash (bash)Per ottenere il token di accesso al cluster OpenShift della Developer Sandbox di Red Hat, devi accedere alla Developer Sandbox e cliccare su “Copy Login Command” per copiare il comando di login con il token. Ecco un esempio di comando di login con token.
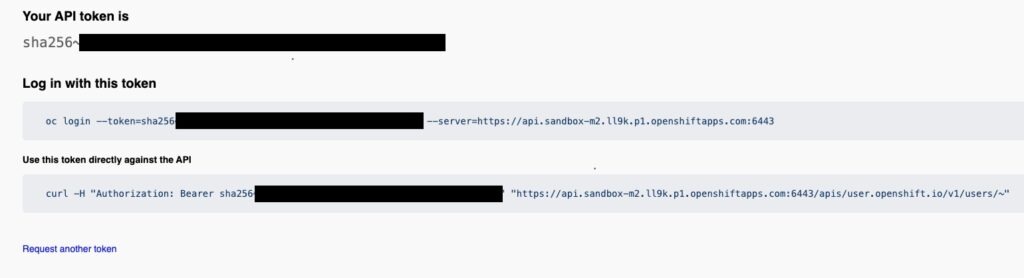
Se il login è riuscito, vedrete un messaggio simile a quello mostrato di seguito, che indica il nome del cluster OpenShift, l’utente con cui avete effettuato il login e il progetto di default in cui siete loggati.
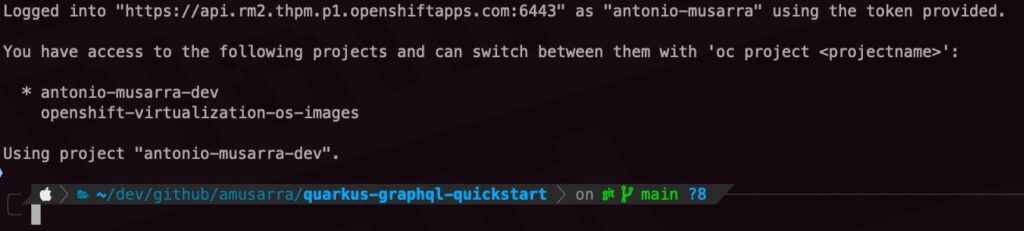
Prima di eseguire il deploy su OpenShift dell’applicazione, è importante assicurarsi che le risorse esterne, come il database PostgreSQL e MinIO (l’Object Store S3), siano disponibili e accessibili dalla nostra applicazione nel cluster OpenShift.
Per i nostri scopi da sviluppatori, possiamo creare in modo semplice, all’interno del cluster OpenShift, tutte le risorse in mancanti.
- Database PostgreSQL
- Object Store S3 utilizzando l’implementazione di MinIO
- Secret del keystore dell’applicazione
Il comando per creare il servizio del database PostgreSQL è mostrato a seguire e fa uso del comando oc new-app.
oc new-app -e POSTGRESQL_USER=quarkus -e POSTGRESQL_PASSWORD=quarkus \
-e POSTGRESQL_DATABASE=quarkus_graphql \
--name=postgresql registry.redhat.io/rhel8/postgresql-16:1-16.1716485357
Code language: Bash (bash)Se l’esecuzione del comando è andata a buon fine, in output dovremmo vedere qualcosa simile a quanto indicato a seguire.
--> Found container image 2428e44 (8 months old) from registry.redhat.io for "registry.redhat.io/rhel8/postgresql-16:1-16.1716485357"
PostgreSQL 16
-------------
PostgreSQL is an advanced Object-Relational database management system (DBMS). The image contains the client and server programs that you'll need to create, run, maintain and access a PostgreSQL DBMS server.
Tags: database, postgresql, postgresql16, postgresql-16
* An image stream tag will be created as "postgresql:1-16.1716485357" that will track this image
--> Creating resources ...
deployment.apps "postgresql" created
service "postgresql" created
--> Success
Application is not exposed. You can expose services to the outside world by executing one or more of the commands below:
'oc expose service/postgresql'
Run 'oc status' to view your app.Code language: PHP (php)Per verificare che il pod sia del database PostgreSQL sia in running, è sufficiente eseguire il comando oc get pods per ottenere un output simile a quello seguente.
NAME READY STATUS RESTARTS AGE
postgresql-554cbb58fc-hlfs2 1/1 Running 0 2m5sIl Pod del database è in running e così come anche il servizio postgresql in listen sulla porta standard 5432 e che potresti verificare usando il comando oc get svc/postgresql il cui output atteso dovrebbe essere come quello indicato subito a seguire.
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
postgresql ClusterIP 172.30.10.240 <none> 5432/TCP 6m10sCode language: HTML, XML (xml)Perfetto! Con il servizio del database PostgreSQL abbiamo finito, ora possiamo passare al servizio dell’Object Store S3.
Per creare ciò che serve per ottenere un servizio di Object Storage S3 usando l’implementazione di MinIO, dobbiamo creare le seguenti risorse sul cluster OpenShift.
- Un Persistent Volume Claim (o PVC) che per gli scopi didattici di questo articolo, è sufficiente che sia anche di 50Mi come request storage.
- Un Deployment per la configurazione di MinIO in termini di container con risorse più che sufficienti per un ambiente di sviluppo.
- Un Service di nome minio che espone la porta TCP/IP 9000 per il servizio di Object Storage e la porta TCP/IP 9090 per la console di amministrazione.
- Due Route per esporre all’esterno del cluster i servizi di MinIO.
All’interno del progetto della nostra applicazione Quarkus di esempio, in src/main/kubernetes, è presente il file minio.yml, dove all’interno sono presenti le descrizioni degli descritti in precedenza.
Eseguendo il comando oc apply -f src/main/kubernetes/minio.yml, creeremo all’interno del cluster OpenShift tutte le risorse necessarie affinché l’applicazione Quarkus possa usare il servizio dell’Object Storage S3.
Il lancio del comando precedente, qualora tutto sia eseguito senza errori, dovrebbe riportare in console quanto mostrato a seguire.
persistentvolumeclaim/minio-pvc created
deployment.apps/minio created
service/minio created
route.route.openshift.io/minio created
route.route.openshift.io/minio-console createdCode language: JavaScript (javascript)Eseguendo il comando oc status, dovremmo anche vedere se tutto effettivamente sia andato per il verso giusto, vedendo un output simile a quello mostrato di seguito.
In project antonio-musarra-dev on server https://api.rm2.thpm.p1.openshiftapps.com:6443
https://minio-antonio-musarra-dev.apps.rm2.thpm.p1.openshiftapps.com to pod port 9000 (svc/minio)
https://minio-console-antonio-musarra-dev.apps.rm2.thpm.p1.openshiftapps.com to pod port 9090
deployment/minio deploys quay.io/minio/minio:latest
deployment #1 running for 4 minutes - 1 podCode language: PHP (php)Ottimo! Tutto è andato bene. Anche il servizio dell’Object Storage S3 è operativo.
Un ultimo prerequisito prima del deploy su OpenShift dell’applicazione Quarkus: dobbiamo creare il Secret che conterrà il keystore, essenziale per abilitare i servizi esposti tramite il protocollo HTTPS.
Questo tipo di operazione è perseguibile, usando il comando: oc create secret generic app-keystore-secret --from-file=app-keystore.p12=src/main/resources/app-keystore.p12
L’esecuzione del comando dovrebbe andare a buon fine mostrando il risultato positivo dell’operazione tramite il messaggio: secret/app-keystore-secret created.
Ci siamo! Non resta altro che eseguire il deploy su OpenShift della nostra applicazione Quarkus di esempio sul cluster OpenShift.
# Comando per eseguire il deploy dell'applicazione Quarkus sul
# cluster OpenShift usando il maven o la CLI di Quarkus
mvn clean package -Dquarkus.openshift.deploy=true
quarkus build -Dquarkus.openshift.deploy=trueCode language: Bash (bash)Se il processo di build e deploy è andato a buon fine, andando su Topology nella console di amministrazione del cluster OpenShift, dovremmo vedere un diagramma simile a quello mostrato nella figura seguente.

Molto bene! L’applicazione è stata installata correttamente con due Pod attivi (vedi configurazione quarkus.openshift.replicas=2). L’immagine a seguire mostra i due Pod dell’applicazione con evidenziati le risorse in termini di memoria.
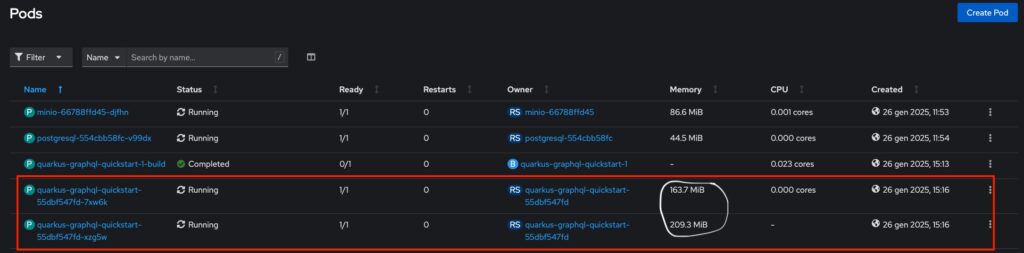
Ecco il tempo di start-up dell’applicazione in modalità JVM, che è di 6.219s. Successivamente, confronteremo questi valori, insieme alla quantità di memoria utilizzata, con la versione nativa dell’applicazione.
2025-01-26 14:16:53,998 INFO [io.quarkus] (main) quarkus-graphql-quickstart 1.0.0-SNAPSHOT on JVM (powered by Quarkus 3.17.7) started in 6.219s. Listening on: http://0.0.0.0:8080 and https://0.0.0.0:8443
2025-01-26 14:16:53,999 INFO [io.quarkus] (main) Profile prod activated.
2025-01-26 14:16:53,999 INFO [io.quarkus] (main) Installed features: [agroal, cdi, hibernate-orm, hibernate-orm-panache, hibernate-validator, jdbc-h2, jdbc-postgresql, kubernetes, minio-client, narayana-jta, rest, rest-jackson, smallrye-context-propagation, smallrye-graphql, smallrye-health, vertx]Code language: JavaScript (javascript)Anche se non è lo scopo di questo articolo, se volessimo testare uno dei servizi dell’applicazione, come le API GraphQL, potremmo eseguire una richiesta utilizzando la cURL seguente.
curl -k -X POST https://<indirizzo-vostra-applicazione>/api/graphql \
-H "Content-Type: application/json" \
-d '{
"query": "query { allBooks {
title
subTitle
isbn
publication
genre
pages
summary
languages
formats
authors {
firstName
lastName
sex
birthDate
}
editor {
name
}
}
}"
}' | jqCode language: Bash (bash)L’output atteso per questa query GraphQL, è la lista dei libri che sono presenti attualmente sul database dell’applicazione. A seguire un estratto.
{
"data": {
"allBooks": [
{
"title": "Networked neural strategy",
"subTitle": "synthesize customized metrics",
"isbn": "9780785316371",
"publication": "2022-11-05",
"genre": "AI",
"pages": 412,
"summary": "Sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.",
"languages": [
"eng",
"deu"
],
"formats": [
"EPUB",
"MOBI"
],
"authors": [
{
"firstName": "Bob",
"lastName": "Williams",
"sex": "M",
"birthDate": "1968-11-01"
},
{
"firstName": "Bob",
"lastName": "Williams",
"sex": "M",
"birthDate": "1968-11-01"
},
{
"firstName": "Emily",
"lastName": "Brown",
"sex": "F",
"birthDate": "1990-02-14"
},
{
"firstName": "Emily",
"lastName": "Brown",
"sex": "F",
"birthDate": "1990-02-14"
}
],
"editor": {
"name": "Global Tech Publications"
}
}
]
}
}
Code language: JSON / JSON with Comments (json)Dopo aver testato con successo uno dei servizi della nostra applicazione appena installata sul cluster OpenShift, possiamo sicuramente ritenerci soddisfatti del risultato ottenuto!
Build e deploy della versione nativa
La compilazione di un’immagine nativa con Quarkus può avvenire in due modi principali: localmente o tramite container. La differenza fondamentale tra questi due approcci risiede nell’ambiente in cui avviene la compilazione e, di conseguenza, nel tipo di eseguibile prodotto.
Quando si esegue una build localmente, si sfrutta un ambiente di sviluppo che ha installato GraalVM o Mandrel, strumenti necessari per la compilazione ahead-of-time (AOT) in codice nativo. In questo caso, il comando di build invoca il compilatore native-image che genera un eseguibile specifico per il sistema operativo su cui si sta lavorando (ad esempio, un eseguibile per Windows, macOS o Linux). Questo approccio richiede una configurazione preliminare dell’ambiente di sviluppo, con l’installazione e la configurazione corretta di GraalVM o Mandrel.
D’altra parte, la compilazione tramite container non richiede l’installazione locale di GraalVM o Mandrel. In questo scenario, Quarkus utilizza Docker o Podman per creare un container in cui avviene la compilazione. Questo container include tutto il necessario, inclusi gli strumenti di compilazione e le dipendenze. La build in container è utile per evitare di dover installare GraalVM localmente o per garantire che l’immagine nativa sia compatibile con ambienti Linux, tipici della produzione.
La scelta tra build locale e build tramite container dipende da diversi fattori. La build locale è ideale se si vuole un eseguibile nativo compatibile con il sistema operativo di sviluppo e si desidera avere il controllo completo sull’ambiente di compilazione.
La build tramite container è più flessibile, non richiede installazioni locali, particolarmente utile per creare immagini native compatibili con ambienti Linux, comuni nei sistemi di produzione e nelle piattaforme cloud. In entrambi i casi, Quarkus permette di personalizzare il processo di compilazione tramite proprietà di configurazione specifiche.
Indipendentemente dal tipo di build, la proprietà quarkus.native.enabled deve essere impostata a true per attivare la compilazione nativa. Inoltre, se si intende eseguire il deploy in OpenShift, è necessario includere l’estensione quarkus-container-image-openshift, la quale si occuperà di generare le risorse OpenShift necessarie per la build e il deployment, incluso un BuildConfig e un ImageStream.
Per eseguire la build nativa in locale, assicuratevi di aver impostato correttamente le variabili di ambiente GRAALVM_HOME e JAVA_HOME, in modo che puntino alla directory di installazione.
Una volta configurato l’ambiente, si può procedere con la compilazione nativa. Per farlo, è necessario attivare il profilo native di Maven. Il comando di build varia a seconda dello strumento di build.
# Build nativa locale usando Maven
mvn package -Pnative
# Build nativa locale usando Quarkus CLI
quarkus build --nativeCode language: PHP (php)Questi comandi avviano il processo di compilazione nativa, che può richiedere diversi minuti e un’elevata quantità di memoria. Il risultato della compilazione sarà un eseguibile nativo specifico per l’architettura della macchina di build, che si troverà nella directory target (Maven).
# Verifica del binario prodotto
file target/quarkus-graphql-quickstart-1.0.0-SNAPSHOT-runner
# Output del comando file
target/quarkus-graphql-quickstart-1.0.0-SNAPSHOT-runner: Mach-O 64-bit executable arm64Code language: Bash (bash)Perché questo eseguibile non funzionerebbe direttamente su OpenShift? La ragione principale è che OpenShift, come molti ambienti di produzione, gira tipicamente su Linux. Un eseguibile compilato per macOS non è compatibile con un sistema operativo Linux e non può quindi essere eseguito direttamente in un container o in un pod di OpenShift. L’immagine a seguire mostra infatti che build sta avvenendo per un macchina con architettura armv8-a (arm64).

Per il deployment su OpenShift è necessario creare una immagine container che contenga l’eseguibile nativo e le sue dipendenze. Questo processo si svolge in modo diverso a seconda che si usi o meno l’estensione quarkus-container-image-openshift. L’estensione genera un BuildConfig, ImageStream e un Deployment.
Nel caso di build locale su macOS, è possibile comunque utilizzare l’eseguibile prodotto all’interno di un Dockerfile per creare l’immagine container da distribuire su OpenShift, ma è importante che l’immagine che verrà utilizzata come base per il container sia per Linux. Invece, quando si utilizza quarkus-container-image-openshift, la build dell’immagine container avviene direttamente nel cluster OpenShift tramite s2i (source-to-image). In questo processo, il JAR (o il binario nativo nel caso di build nativa) viene trasferito al cluster OpenShift, dove viene costruita l’immagine container usando le immagini base specificate in quarkus.openshift.base-jvm-image o quarkus.openshift.base-native-image. Quindi l’immagine creata con s2i sarà già compatibile con l’ambiente Linux di OpenShift.
Per riassumere, sebbene sia possibile creare un eseguibile nativo su macOS, questo non sarà direttamente utilizzabile su OpenShift. Per il deploy, è necessario creare un’immagine container usando un Dockerfile o sfruttare l’estensione quarkus-container-image-openshift, la quale offre un processo di build specifico per OpenShift tramite S2I che crea un’immagine nativa compatibile con Linux.
Utilizzando quindi l’opzione -Dquarkus.native.container-build=true e -Dquarkus.openshift.deploy=true la build sarà eseguita in modalità container e l’immagine container finale costruita direttamente sul cluster OpenShift.
Adesso, il file nativo dell’applicazione generato è per il target corretto: architettura x86-64 Linux.
# Verifica del binario prodotto
file target/quarkus-graphql-quickstart-1.0.0-SNAPSHOT-runner
# Output del comando file
target/quarkus-graphql-quickstart-1.0.0-SNAPSHOT-runner: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=07b4e3eb12f41264be402bc344fb5e80c1a7bbd8, not strippedCode language: Bash (bash)Come mostrato nell’immagine seguente, la build dell’immagine nativa finale è stata eseguita sul cluster OpenShift grazie al BuildConfig quarkus-graphql-quickstart, con il risultato finale dell’immagine nativa quarkus-graphql-quickstart:1.0.0-SNAPSHOT.
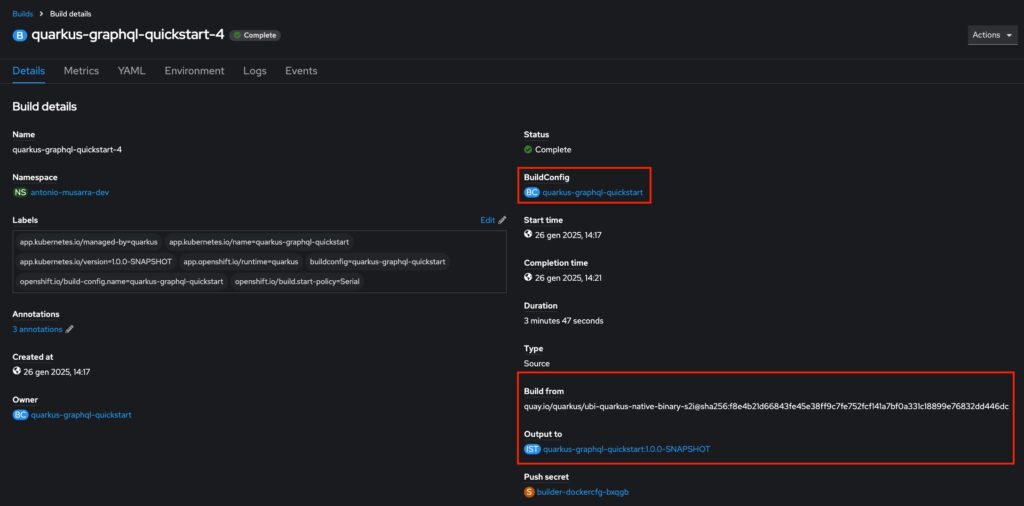
L’immagine container della nostra applicazione Quarkus è disponibile nell’image repository del cluster OpenShift. Per vedere tutti i dettagli, è possibile eseguire il comando oc describe ImageStream/quarkus-graphql-quickstart, il cui output dovrebbe essere simile a quello mostrato di seguito.
Name: quarkus-graphql-quickstart
Namespace: antonio-musarra-dev
Created: 47 minutes ago
Labels: app.kubernetes.io/managed-by=quarkus
app.kubernetes.io/name=quarkus-graphql-quickstart
app.kubernetes.io/version=1.0.0-SNAPSHOT
app.openshift.io/runtime=quarkus
Annotations: app.openshift.io/vcs-uri=<<unknown>>
app.quarkus.io/build-timestamp=2025-01-26 - 13:17:17 +0000
app.quarkus.io/quarkus-version=3.17.7
Image Repository: default-route-openshift-image-registry.apps.rm2.thpm.p1.openshiftapps.com/antonio-musarra-dev/quarkus-graphql-quickstart
Image Lookup: local=true
Unique Images: 2
Tags: 1
1.0.0-SNAPSHOT
no spec tag
* image-registry.openshift-image-registry.svc:5000/antonio-musarra-dev/quarkus-graphql-quickstart@sha256:c88d5414a1c4b64c11763dafab2796a690ad1d11c8965c1dfa99bc15f15cb037
23 minutes ago
image-registry.openshift-image-registry.svc:5000/antonio-musarra-dev/quarkus-graphql-quickstart@sha256:391f4e5de02197b10fed63ed0df9211297660bf83378a984aa4998102e26fea4
43 minutes agoCode language: JavaScript (javascript)L’immagine seguente mostra il Pod dell’applicazione Quarkus in modalità nativa in esecuzione. Come si può notare, l’uso della memoria è significativamente inferiore rispetto alla versione in modalità JVM, e anche i tempi di start-up sono decisamente più rapidi.
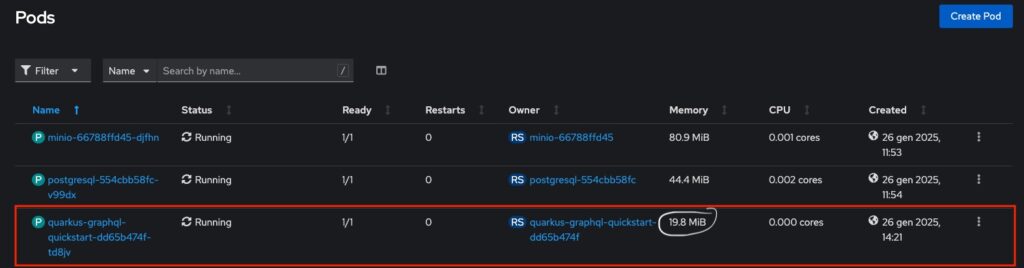
A seguire è mostrato il tempo di start-up dell’applicazione in modalità nativa che è di 0.320s.
2025-01-26 13:21:26,143 INFO [io.quarkus] (main) quarkus-graphql-quickstart 1.0.0-SNAPSHOT native (powered by Quarkus 3.17.7) started in 0.320s. Listening on: http://0.0.0.0:8080 and https://0.0.0.0:8443
2025-01-26 13:21:26,143 INFO [io.quarkus] (main) Profile prod activated.
2025-01-26 13:21:26,143 INFO [io.quarkus] (main) Installed features: [agroal, cdi, hibernate-orm, hibernate-orm-panache, hibernate-validator, jdbc-h2, jdbc-postgresql, kubernetes, minio-client, narayana-jta, rest, rest-jackson, smallrye-context-propagation, smallrye-graphql, smallrye-health, vertx]Code language: JavaScript (javascript)La compilazione in immagine nativa con GraalVM, sebbene offra notevoli vantaggi in termini di tempo di avvio e consumo di memoria, potrebbe non essere la soluzione ideale per tutte le applicazioni Quarkus. Ci sono diverse ragioni per cui la build nativa potrebbe non essere appropriata o potrebbe non funzionare correttamente in determinati scenari.
Per questa applicazione Quarkus di esempio, sono state adottate specifiche configurazioni per garantire che la versione nativa funzioni correttamente. Per approfondire le diverse strategie per migrare da JVM mode (JIT) a AOT, consiglio di esplorare il progetto Graalkus: A Quarkus MicroProfile Demo Migrating from JIT to AOT with GraalVM.
Risorse Utili
Per approfondire ulteriormente gli argomenti trattati in questo articolo e per avere una visione più completa su Quarkus, OpenShift e le tecnologie correlate, ecco una lista di risorse utili.
- Documentazione Ufficiale di Quarkus: la guida ufficiale di Quarkus è una risorsa fondamentale per comprendere appieno il framework. In particolare, le sezioni relative a container images, Kubernetes e OpenShift sono particolarmente rilevanti per gli argomenti trattati. Si possono trovare guide specifiche per la configurazione di OpenShift, per le opzioni delle immagini container e per l’utilizzo di Knative.
- Estensione Quarkus OpenShift: l’estensione quarkus-openshift facilita la creazione e la distribuzione di applicazioni Quarkus su OpenShift. Questa estensione agisce come un wrapper configurando l’estensione Kubernetes con impostazioni predefinite per semplificare l’avvio dell’applicazione su OpenShift.
- MicroProfile Health: per approfondire le specifiche MicroProfile Health, si può fare riferimento alla documentazione di SmallRye Health. Questa estensione fornisce le probe di Liveness, Readiness e Startup, essenziali per le applicazioni cloud-native.
- Client Kubernetes e OpenShift: Quarkus fornisce le estensioni quarkus-kubernetes-client e quarkus-openshift-client che integrano il client Fabric8 per un accesso programmatico alle API di Kubernetes e OpenShift. L’articolo cita anche un articolo su come utilizzare il client Fabric8.
- Red Hat Developer Sandbox: per sperimentare con OpenShift senza dover configurare un’infrastruttura complessa, si può utilizzare la Developer Sandbox di Red Hat, un ambiente cloud preconfigurato e pronto all’uso. È disponibile un link per registrarsi gratuitamente e per installare la CLI di OpenShift.
- Progetto di Esempio: il progetto di esempio quarkus-graphql-quickstart su GitHub è una risorsa pratica per vedere in azione i concetti discussi nell’articolo. Questo progetto include l’integrazione di Quarkus con GraphQL, JPA/Hibernate, API RESTful, l’estensione OpenShift e la gestione di configurazioni multiple.
- Repository GitHub quarkus-graphql-quickstart: per maggiori informazioni sull’applicazione che sarà oggetto del deploy su OpenShift, si può consultare il progetto pubblicato su questo repository https://github.com/amusarra/quarkus-graphql-quickstart GitHub.
- Graalkus: A Quarkus MicroProfile Demo Migrating from JIT to AOT with GraalVM: per approfondire le strategie per la migrazione da JVM mode a AOT, questo progetto può essere utile.
Queste risorse forniscono una base solida per approfondire la conoscenza di Quarkus e OpenShift, e per affrontare con successo il deployment di applicazioni in ambienti cloud-native.
Conclusioni: Missione Deploy su OpenShift Compiuta!
Siamo arrivati alla fine di questo viaggio nel mondo di Quarkus e OpenShift! Abbiamo fatto un bel po’ di strada insieme, partendo dalle basi fino ad arrivare al deploy della nostra applicazione di esempio. Ma cosa abbiamo imparato di preciso? E soprattutto, abbiamo raggiunto il nostro obiettivo di far girare la nostra applicazione Quarkus su OpenShift in modo ottimale? La risposta è un sonoro sì!
In questo articolo, abbiamo visto passo dopo passo come
- Configurare l’ambiente: abbiamo preparato il terreno, assicurandoci di avere tutti gli strumenti necessari a portata di mano, dal cluster OpenShift alla CLI, passando per JDK, Maven e gli altri tool indispensabili.
- Sfruttare l’estensione OpenShift: abbiamo scoperto che questa estensione è un vero e proprio asso nella manica, semplificando di molto la creazione di immagini container, la configurazione delle risorse OpenShift e il deployment automatico.
- Adattare il nostro progetto: abbiamo aggiunto le dipendenze necessarie, in particolare
quarkus-openshiftesmallrye-health, e configurato l’esposizione esterna dell’applicazione e il supporto per HTTPS. - Gestire la sicurezza: abbiamo imparato a proteggere le informazioni sensibili attraverso l’uso dei Secret, un aspetto fondamentale per qualsiasi applicazione che vada in produzione.
- Configurare le risorse esterne: abbiamo creato le risorse per PostgreSQL e MinIO all’interno del cluster, indispensabili per il funzionamento della nostra applicazione.
- Eseguire il deploy: abbiamo portato a termine il deploy della nostra applicazione, verificando che tutto funzionasse a dovere.
- Build e deploy nativo: abbiamo anche esplorato il mondo della build nativa con GraalVM, vedendo come questa possa portare a performance eccezionali, riducendo drasticamente i tempi di startup e l’uso di memoria.
Grazie all’estensione quarkus-openshift, abbiamo automatizzato gran parte del processo di deployment, ottenendo un’applicazione funzionante su OpenShift in tempi rapidi. Abbiamo dimostrato che è possibile creare applicazioni Quarkus altamente performanti e facilmente gestibili in un ambiente cloud come OpenShift.
Non solo, ma abbiamo anche appreso come ottimizzare l’applicazione per il cloud, implementando le probe di MicroProfile Health, che sono fondamentali per garantire la stabilità e la resilienza delle nostre applicazioni in ambienti containerizzati. Abbiamo inoltre visto come configurare i Secret in modo da proteggere le nostre informazioni sensibili e come configurare la build delle immagini container tramite la strategia s2i.
In definitiva, abbiamo visto che Quarkus e OpenShift sono un connubio perfetto, capace di semplificare notevolmente il processo di sviluppo e deployment delle applicazioni cloud-native. Quindi, se avevate dubbi, speriamo che questo articolo li abbia spazzati via!
Ora che avete tutte le carte in regola, non vi resta che mettere in pratica quanto appreso e far volare le vostre applicazioni su OpenShift. Buon deploy a tutti!
