En el mundo del Machine Learning (ML), existen algoritmos que nos permiten tomar decisiones inteligentes a partir de los datos. Uno de los más intuitivos y poderosos son los árboles de decisión. ¿Te imaginas poder predecir si un cliente comprará un producto, diagnosticar una enfermedad o incluso determinar el mejor camino para llegar a tu destino? Los árboles de decisión hacen esto posible.
Son una de las técnicas más populares en el mundo del aprendizaje automático y la ciencia de datos. Son fáciles de entender, interpretar y utilizar para resolver problemas de clasificación y regresión. En este artículo, exploraremos en detalle qué son, cómo funcionan, ventajas, desventajas y cómo implementarlos.

¿Qué son los Árboles de Decisión?
Es como un diagrama de flujo que te guía a través de una serie de preguntas o decisiones para llegar a una conclusión. Imagina que estás decidiendo si ir de picnic. Primero, miras el cielo: ¿está soleado? Si no, te quedas en casa. Si sí, ¿hace calor? Si no, llevas una chaqueta. Si sí, ¿tienes comida preparada? Y así sucesivamente. ¡Eso es un árbol de decisión en acción!
En ML, funcionan de manera similar, pero con datos. Analizan características (como el clima, la temperatura, etc.) para tomar decisiones y predecir resultados (como si ir de picnic o no).
Anatomía de un Árbol de Decisión
- Nodo Raíz: Es el punto de partida del árbol, donde se toma la primera decisión.
- Ramas: Representan las diferentes opciones o resultados de una decisión.
- Nodos Internos: Son puntos de decisión intermedios que dividen los datos en subgrupos.
- Nodos Hoja: Son los puntos finales del árbol, donde se llega a una conclusión o predicción.
Es un modelo predictivo de aprendizaje supervisado que organiza datos en una estructura jerárquica en forma de árbol, que representa una serie de decisiones y sus posibles consecuencias. Se compone de nodos internos que representan una condición sobre características o atributos, ramas que indican el resultado de esas condiciones (los valores de los atributos) y hojas que contienen las predicciones, decisiones finales o resultados.
¿Cómo se Construye un Árbol de Decisión?
Implica seleccionar las mejores características para dividir los datos en cada nodo. Para ello, se utilizan métricas como la entropía y la ganancia de información.
- Entropía: Mide la incertidumbre o impureza de un conjunto de datos.
- Ganancia de Información: Mide cuánto se reduce la entropía al dividir los datos en función de una característica.
El algoritmo busca las características que maximizan la ganancia de información en cada paso para construir el árbol de manera óptima.
Ventajas:
- Fáciles de entender: Son intuitivos y pueden ser visualizados, lo que facilita su comprensión y comunicación.
- No requieren normalización de datos: Pueden manejar datos sin necesidad de escalarlos. A diferencia de otros algoritmos, no es necesario normalizar o estandarizar los datos antes de usarlos.
- Capacidad de manejar datos categóricos y numéricos: Pueden trabajar con diferentes tipos de datos. Pueden trabajar con datos que no son numéricos, como colores o tipos de frutas.
- Versátiles y aplicables a diversos problemas: Se pueden utilizar para una amplia gama de problemas, desde clasificación (predecir categorías) hasta regresión (predecir valores numéricos).
Desventajas:
- Pueden ser propensos a sobreajuste (memorizar los datos de entrenamiento).
- Pueden ser sensibles a pequeñas variaciones en los datos.
- Pueden crear árboles complejos y difíciles de interpretar si no se podan.
Aplicaciones de los Árboles de Decisión
- Medicina: Diagnóstico de enfermedades, predicción de riesgos.
- Finanzas: Evaluación de riesgos crediticios, detección de fraudes.
- Marketing: Segmentación de clientes, recomendación de productos.
- Recursos Humanos: Selección de candidatos, evaluación de desempeño.

Implementación de Árboles de Decisión
Implica dividir iterativamente el conjunto de datos en subconjuntos más pequeños basados en un atributo de decisión. La selección del mejor atributo se realiza utilizando métricas como la ganancia de información o el índice de Gini.
- Instalación de Librerías Necesarias
pip install scikit-learn pandas numpy matplotlib- Importación de Librerías y Carga de Datos
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
# Cargar dataset de ejemplo (Iris)
from sklearn.datasets import load_iris
data = load_iris()
X = data.data
y = data.targetLenguaje del código: PHP (php)- División de los Datos en Conjunto de Entrenamiento y Prueba
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)- Creación y Entrenamiento del Modelo
# Crear el modelo
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)
# Entrenar el modelo
clf.fit(X_train, y_train)Lenguaje del código: PHP (php)- Evaluación del Modelo
# Predicciones
y_pred = clf.predict(X_test)
# Calcular precisión
accuracy = accuracy_score(y_test, y_pred)
print(f'Precisión del modelo: {accuracy:.2f}')Lenguaje del código: PHP (php)- Visualización del Árbol de Decisión
plt.figure(figsize=(12,8))
plot_tree(clf, feature_names=data.feature_names, class_names=data.target_names, filled=True)
plt.show()Lenguaje del código: PHP (php)Poda y Optimización del Modelo
Para evitar el sobreajuste, se pueden aplicar técnicas de poda como limitar la profundidad del árbol:
clf = DecisionTreeClassifier(max_depth=4, min_samples_split=5, random_state=42)
clf.fit(X_train, y_train)Ejemplo: Clasificación con Árbol de Decisión
Vamos a crear un modelo de clasificación utilizando un árbol de decisión con la biblioteca scikit-learn.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score, classification_report
import matplotlib.pyplot as plt
# Datos de ejemplo
data = {
'Edad': [25, 45, 35, 50, 23, 33, 40, 37],
'Salario': [50000, 100000, 75000, 120000, 45000, 70000, 95000, 80000],
'Compra': ['No', 'Sí', 'Sí', 'Sí', 'No', 'Sí', 'Sí', 'No']
}
df = pd.DataFrame(data)
# Codificación de datos categóricos
df['Compra'] = df['Compra'].map({'No': 0, 'Sí': 1})
# División del conjunto de datos
X = df[['Edad', 'Salario']]
y = df['Compra']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Creación del modelo de árbol de decisión
model = DecisionTreeClassifier()
model.fit(X_train, y_train)
# Predicciones
y_pred = model.predict(X_test)
# Evaluación del modelo
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(classification_report(y_test, y_pred))
# Visualización del árbol de decisión
plt.figure(figsize=(12,8))
plot_tree(model, feature_names=X.columns, class_names=['No', 'Sí'], filled=True, rounded=True, fontsize=12)
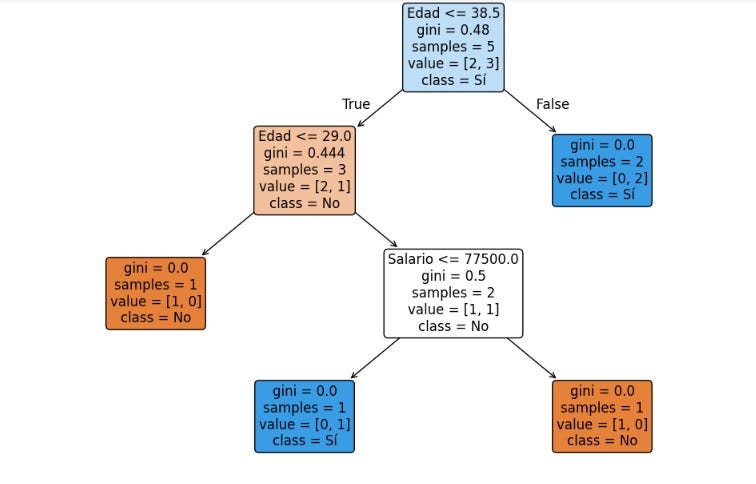
plt.show()Lenguaje del código: PHP (php)Este código crea un modelo para predecir si una persona comprará o no (sí/no) en función de su edad y salario. Para generar un gráfico visual se utiliza plot_tree de sklearn.tree.
Ejemplo: Regresión con Árbol de Decisión
Vamos a crear un modelo de regresión utilizando un árbol de decisión con la biblioteca scikit-learn.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# Datos de ejemplo
data = {
'Horas de Estudio': [1, 2, 3, 4, 5, 6, 7, 8],
'Nota': [50, 55, 60, 65, 70, 75, 80, 85]
}
df = pd.DataFrame(data)
# División del conjunto de datos
X = df[['Horas de Estudio']]
y = df['Nota']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Creación del modelo de árbol de decisión
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
# Predicciones
y_pred = model.predict(X_test)
# Evaluación del modelo
print(f"MSE: {mean_squared_error(y_test, y_pred)}")
print(f"Predicciones: {y_pred}")
# Visualización del árbol de decisión
plt.figure(figsize=(12,8))
plot_tree(model, feature_names=X.columns, filled=True, rounded=True, fontsize=12)
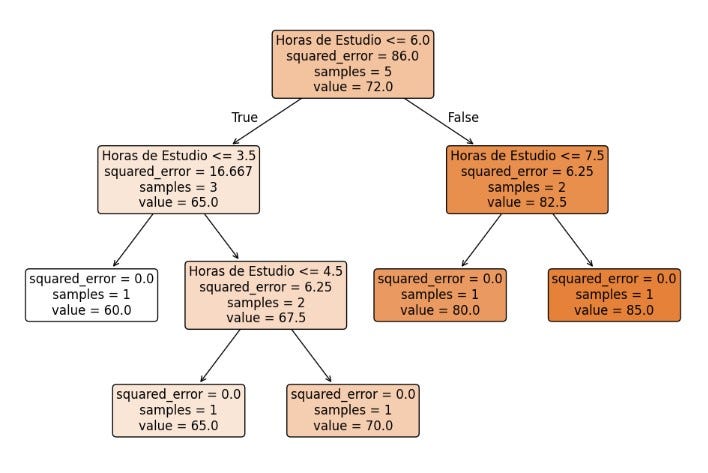
plt.show()Lenguaje del código: PHP (php)Este código, crea un modelo para predecir la nota de un estudiante según sus horas de estudio.
Consejos para Usar Árboles de Decisión
- Poda: Limita la profundidad del árbol para evitar el sobreajuste.
- Validación Cruzada: Utiliza técnicas de validación cruzada para evaluar el rendimiento del árbol en datos no vistos.
- Ensamblado: Combina varios árboles de decisión para mejorar la precisión y robustez (Bosques Aleatorios, Gradient Boosting).
Conclusión
Los árboles de decisión son una herramienta fundamental en el mundo del Machine Learning. Su capacidad para manejar datos complejos y producir modelos interpretables los convierte en una excelente opción para muchos problemas de clasificación y regresión. Su capacidad para tomar decisiones inteligentes a partir de los datos los convierte en aliados poderosos para resolver problemas complejos y mejorar nuestra vida.

