
Introduction
We all use end-to-end encryption (E2EE) daily for messaging, using apps such as WhatsApp or Telegram. But what does E2EE mean? Aren’t any two clients communicating via TLS already protected end-to-end? Isn’t any website using HTTPS safe from a man-in-the-middle attack? The man-in-the-middle might be shut out, but what if the provider decides to look at your data? TLS terminates at the server, and whoever controls the server could read your messages. If the provider can be trusted to do the right thing, user privacy is maintained, but just how trustworthy is any provider?
Would you trust your landlord enough to give them a second key to your flat, just because the flat happens to be in his house? Of course, the answer is “no”. This answer remains the same when it comes to messaging, and cloud storage in particular.

When files are uploaded to Google Drive, the transfer of data is protected by TLS, and Google also makes sure the data is encrypted at rest. But Google is also in possession of the encryption key. This means that there is still a risk of data leaking in its unencrypted form. Ideally, as in the landlord example above, it’s preferable not to share the encryption keys with the cloud storage provider, but how can we be sure that not even the landlord has the keys to your front door? The answer is zero-knowledge encryption – let’s dig a little deeper.
Different types of encryption on the market, and why zero-knowledge?
The GDPR requires data controllers to protect personal data. As a consequence, data controllers use two kinds of encryption to prevent unauthorised access or data leakage: encryption at rest and encryption at transit.
Encryption at rest
Encryption at rest prevents possible attackers from accessing unencrypted data on a disk. Typically, encryption of data at rest is accomplished using a symmetric key for encryption and the same key for decryption. Many cloud storage solutions rely on AES128 or AES256 for this.
Encryption in transit
The concept of encryption in transit includes the encryption and decryption of data from and into its plain (decrypted) form both before and after transmission. TLS is the best example of this kind of transport security. In TLS, a server must first prove its identity by providing a certificate from a Certificate Authority (CA) trusted by the user requesting the connection. The certificate contains the server’s public key as well as its DNS hostname. Then, the server and client systems use a handshake procedure to establish a session-specific shared key. There are several standards which can be used as key agreement protocols, all based on Diffie Hellman (DH). This article focuses on the differences between Ephemeral Diffie Hellman (DHE) and static Diffie Hellman (DH), but interested readers might turn to the standard itself to get a complete list of DHE variants such as Elastic Curve DHE (ECDHE). In contrast to static DH, DHE variants generate a new private key for every communication, in the process agreeing a shared secret with the server. This approach offers forward secrecy (past communication is still protected even if the long-term private key is exposed). DHE cannot offer authenticity (the key is different every time) and thus is used in combination with RSA or other established standards. After a shared key is established via a DH variant, this is used to encrypt subsequent communication using a symmetric cipher, typically AES. As noted at the beginning of this article the most visible use of TLS is in the HTTPS protocol. There are several additional TLS enabled protocols, including FTP, SMTP, and IMAP.
Zero-Knowledge Architecture
Encryption at rest in combination with encryption in transit makes sure the unencrypted data is never exposed even if a data breach occurs; in other words it is never exposed to anyone unauthorised, only to the owner and the cloud storage provider. However, when files are transferred to cloud storage, in the moment following transmission and before re-encryption, plain data is available to your cloud storage provider. Furthermore, the cloud provider has the keys to your encrypted data at rest. Here is where the zero-knowledge approach comes into play. If a cloud storage application follows the zero-knowledge design principle (or uses a so-called zero-knowledge architecture) it services protected client data without ever having unencrypted access to it (hence the name zero-knowledge or zero access). “Nobody can access your files without your permission – not even us.“ is the motto of Cubbit, a cloud storage provider that has adopted this approach. If a cloud storage provider cannot access your data, there’s no need to worry about trusting them.
How does zero-knowledge encryption work?
Before talking about the ‘how’, let’s clarify some terminology, as it is easy to get lost in buzzwords. If the zero-knowledge architecture (ZKA) of an application (cloud storage solutions included) is under discussion, the topic is the encryption of data before it is sent to the server, or, in more abstract terms, it is a means of avoiding providing knowledge about the data to the provider.
Zero-knowledge architectures can be implemented using end-to-end encryption (E2EE), utilising symmetric and asymmetric ciphers.
Matthias Dugué shows how a simple zero-knowledge backend can be implemented based on a simple E2EE approach. Some possible functionalities include: encrypting the data to be sent using a symmetric key; generating a new symmetric key for each data transfer and sharing the symmetric key with the server by encrypting it with the public key of the receiving user. This brings TLS to mind, but now the data is protected from the cloud storage provider via a similar approach. The role of a zero-knowledge backend is typically to store encrypted data and manage public keys. To share a file with a different user without the backend having any access to the data would require encrypting the file with a secret key. The encrypted file can be sent through a zero-access backend to the user you shared the file with. The user on the other side can use their own private key to decrypt the original secret, which can then be used to get the original file. This approach is called key wrapping. The symmetric secret-key is signed (encrypted) with the public key of a certain user.
As we have seen, zero-knowledge architectures can use simple E2EE techniques that are probably already familiar to most readers. However, the term ‘zero-knowledge’ emerges from another category of cryptographic methods called zero-knowledge proof, also seen in ZKAs. So what is a zero-knowledge proof (or zero-knowledge protocol)(ZKP)? A ZKP is a challenge/response protocol used by two parties to provide proof of the correctness of their secret key without any possibility of deducing the content of the original secret. An authentication procedure requires a prover (Alice) to respond to challenges issued by a verifier (Bob). Alice must pass all Bob’s challenges to prove her identity. In ZKP the verifier (Bob) is unable to learn anything about the secret. A prominent example of ZKP is the Goldreich-Micali-Wigderson (GMW) protocol: the protocol is based on graph isomorphisms. For those readers who do not remember their discrete maths lectures: two graphs – A and B – are isomorphic if there exists a permutation P of vertices on A, mapping any edge (a1, a2) in A to an edge in B. Let’s review the Wikipedia example of two isomorphic graphs below:
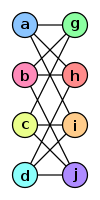
Figure 1 Graph A
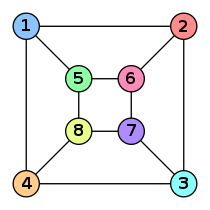
Figure 2 Graph B
Permutation P
The verifier needs to prove that they know the above permutation (or the secret) by transforming one of the graphs with another random permutation R and showing the isomorphy between the resulting graph H and A or B (A or B is chosen by verifier). The challenge is repeated with different graph pairs until the verifier is satisfied. The problem is NP-hard and thus suited for such tasks as authentication (Pádraig Flood, 2014).
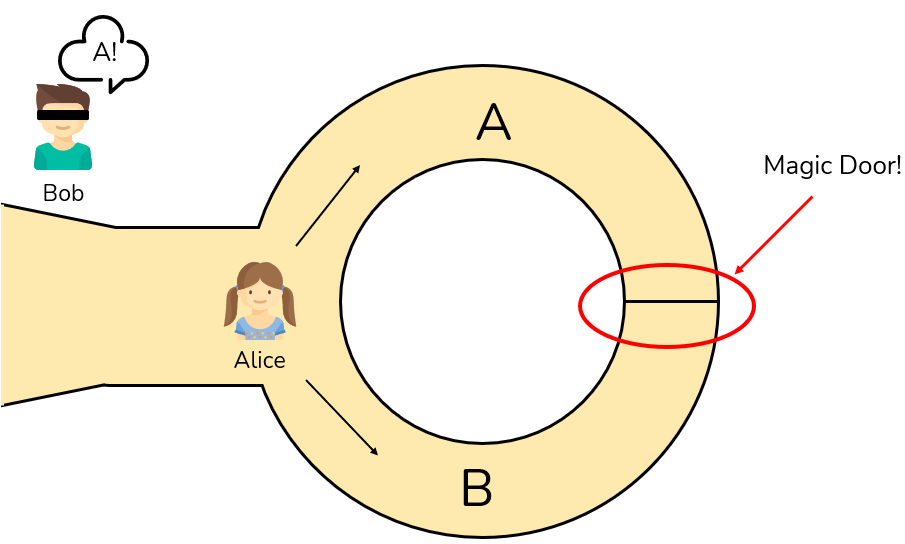
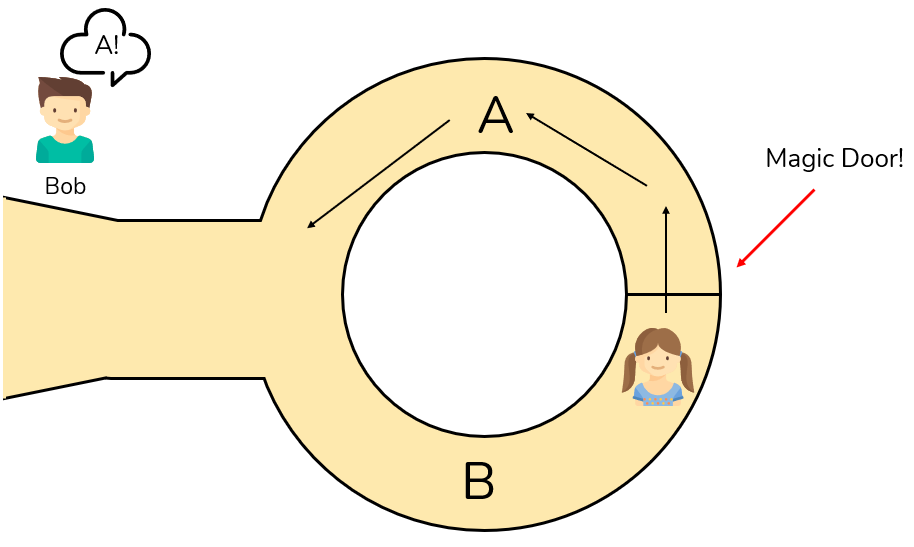
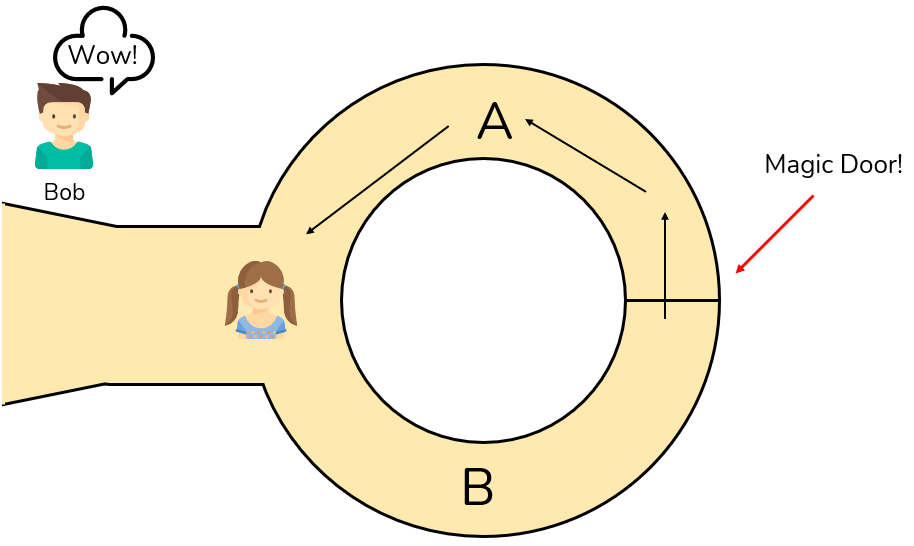
An abstract example that better illustrates the workings of ZKP is Ali Baba’s cave. We have the same two parties involved: Bob the verifier, and Alice the prover. Alice walks into a ring-shaped cave. In the middle of the cave is a door. Alice must demonstrate to Bob that she has the secret knowledge (or the key) to open the door without exposing her knowledge to Bob or the world at large. So how can Alice prove that she knows the password? The entrances to the ring-shaped cave are labelled A and B. Bob waits outside the cave while Alice enters through A or B. Then Bob goes to the entry of the cave and shouts either “A” or “B” and Alice should exit through the entrance point Bob has named. If Alice does NOT know the secret (or does NOT have the key to the door) she still has a 50% chance of exiting in the right direction, but if Bob repeats this process 20 times, the chance of Alice guessing the secret is well below zero (about one chance in a million, to be more specific).
Zero-knowledge approaches do not end with E2EE encryption or authentication alone. Some advanced appliances are able to search through encrypted data or database operations using encrypted data without first going through a decryption process.
The benefits of zero-knowledge encryption and p2p file storage
As discussed above, zero-knowledge can provide a new dimension of protection for data. What if there was another step that went further in terms of the security of cloud storage? What if each file was to be distributed among different locations, broken into encrypted chunks and shredded into fragments, and replicated across different machines. The leakage of data becomes even harder. The file is not stored in a single location, so there is no single point of failure. This is the result of combining zero-knowledge with the peer-to-peer (P2P) approach.
Cubbit provides a cloud storage solution that is based on these principles: distributed and completely user-powered. How does it work? Service users acquire a so-called Cubbit Cell that acts as a peer in the ‘Swarm’, a P2P network of other Cells. Data is stored on multiple peers within a Swarm and no one except the owner can access it (not even Cubbit). The solution uses a hybrid P2P network, which means there are centralised components, known as coordinators, managing which resources can be stored on which peers (an approach similar to one readers might know from μTorrent).
The coordinator makes use of a fitness function to minimise the probability of losing files, namely distributing files as widely as possible to make storage disaster-proof, and as close as possible to reduce network latency. The coordinator also has no access to user data due to the zero-knowledge nature of the architecture. For the client-side encryption, the following zero-knowledge approach is used: a client generates a new AES 256 key and uses it to encrypt the file. These keys (different for each device) are stored on the coordinator in encrypted form (key wrapping).
The last encryption step uses a master key which is derived from the user’s password. File redundancy is achieved as follows: each of N+K shards is stored on a different Cell, with N being the number of shards a file is cut into and K the number of parity shards, in a Reed-Solomon format (K parity shards are hosted by K hosting peers for recovery purposes). In Reed Solomon, if you can reach N of N+K Cells, retrieval of a file is still possible. The authors claim that in this setup the probability of downtime is lower than 0.000001. No single Cell contains the whole file, but stores only shards of encrypted chunks of files belonging to other people. The coordinator triggers a recovery process whenever the number of shards reaches N + K/2. Recovery involves contacting other peers to reach the original shard count (of online shards), namely N+K. Cubbit claims the redundancy parameters are chosen to guarantee a 99.0000% statistical uptime.
Everything that has been discussed until this point is more or less achievable in pure Cloud (private or public). The previously-mentioned Reed-Solomon codes are also used to replicate a file among nodes in a data centre (as well as to protect blocks of data stored on a DVD as a precaution against corruption). However, there is a drawback: Cloud solutions require recurring payments, e.g., €119.88 per year for 2 TB on Dropbox. In a P2P network, users only need to join the Swarm once. For purposes of comparison, joining Cubbit requires buying a Cell – a one-off payment of €349 – and puts 1TB at your service. These figures show that Cubbit provides a service with comparable cost-efficiency (and a single payment) while integrating the zero-knowledge approach.
Last, but not least, there is one final advantage worth noting! In the last few years, many people have become increasingly aware of the impact their personal carbon footprint has on global warming. We consider our carbon footprint when choosing an electricity provider, buying a fridge, or just planning the number of flights taken for business trips. The COVID crisis showed everyone that business trips can be reduced. The same principles hold when it comes to online activities. According to a report from the KTH Royal Institute of Technology in Sweden, the internet’s carbon footprint accounts for ten percent of the total global energy demand, with cloud data centres contributing a significant amount of that (Lundén, 2018). Thus, cloud storage is another area in which there is a choice to be made between supporting power-hungry data centres or going green by using a P2P network of low-power consumption ARM-based single-board devices (such as Cubbit’s Cells). Cubbit recently published a paper that compares the power consumption of both data storage and data transfer using their P2P approach with that of centralised cloud storage. Without replicating the maths here (interested readers can access the paper directly) the result is clear: Cubbit’s P2P-based cloud storage is up to 10 times greener, allowing the average user to save 40kg CO2 per TB stored each year. For private users and companies with strict privacy requirements and energy efficiency goals, it might well be the solution to go with.
How to get started
Cubbit offers different plans and options. Cells are available from 1TB/€349, with 30-Day trials available (with full refund), and a four-year warranty!
P.S. Cubbit has created an exclusive challenge for the Codemotion community: Play Storage Snake, save as many files as you can, and increase your score as much as you can to get the coolest surprise from the Swarm!



