
The Internet is pretty big. But when you need a hand in this ocean of useless data, a search engine is your friend.
In this journey through the web, we will understand which algorithms and techniques form a search engine and what we need to create one.
Different kinds of queries, different kinds of results
As you may know, a search engine is not as simple as it looks. On our end, we just type a couple of words and, in a matter of seconds, we have what we want. But under the surface, a lot is going on.
First, depending on the information we’re looking for, a search engine uses a different representation.
For instance, if we ask when a certain event will take place, a search engine will just answer our question. After all, that is what we needed, and the search engine knows it.
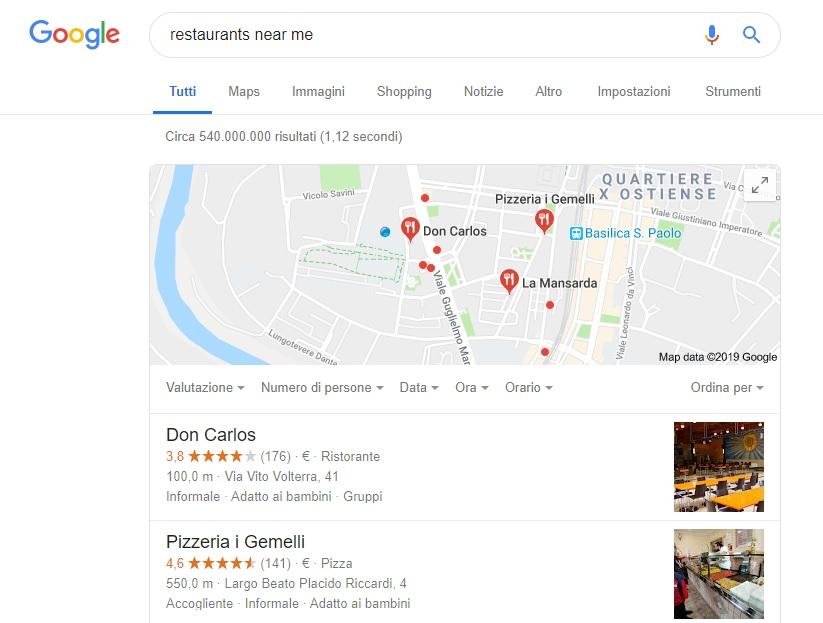
A similar approach is applied to location searches. The difference is that, typically, asking for a place to eat will result in a list of nearby restaurants. This time the search engine knows that the restaurant we want is in that list but can’t possibly know our preferences.
But what about more complex questions? This is where the magic begins.
Before searching
If you ever use Google, you probably noticed that, for every question, a massive number of results is shown. But how can a search engine possibly know that many pages? The answer is Crawling.
Crawling is a fundamental operation for a search engine because it scans the internet starting from all known URLs and, moving concentrically from link to link, creates a sort of map. Every new page that has already been crawled is then added to a Bloom Filter, a probabilistic data structure.
The next step is to know what the actual content of these pages is. For this purpose, we need to introduce a new operation: Indexing.
What happens is that, for every term of interest, the search engine scans documents and counts occurrences. This produces a list of pages for every given term, called Posting List. Having this makes it really easy to know which documents are more suitable for any given request.
Now that we have a list of accessible pages and we know their content, we need a way to decode a user’s question and to make it easily understood by a search engine. This operation is called Parsing.
First, the search engine identifies the kind of document that is needed and the language used. Then it tokenises words, removing punctuation and reducing letters to lower-case. Next, it removes stop-words like “a” or “the”. Finally, the search engine looks for synonyms and related words. Now we have a list of basic keywords and parsing is complete.
But this is only the beginning.
The life-cycle of a Query
Starting from the moment we type our question and click enter, a query is born. However, many steps are required before an acceptable answer is produced. Let’s look at it like a production line; using our query as a model, the search engine will take raw results and refine them until they’re ready to use.
To begin, the search engine – once it has received and parsed our query – will start looking it up in posting lists.
This will usually result in billions of positive matches. We obviously need to process this huge amount of data to determine which documents are more suitable. For this purpose, Boolean Logic is applied, letting only documents that have multiple different terms from query survive.
Now we have a stricter and more relevant list, but we still need to rank and sort the results. To achieve this, a search engine can use different algorithms like TF-IDF, a function that evaluates the ratio between the searched term and the total amount of words in a document. In any case, the outcome will be a list of top-k documents.
The final stage is once again a ranking one, just more complex. The top-k documents list is still too big and not refined enough, so how can we perfect the result?
The answer is Cascade Ranking. With the help of different algorithms, the search engine can perform re-ranking and build a multi-level architecture, more complex every time. In this re-ranking, the page’s popularity is taken into consideration. The simplest way to measure popularity on the internet is by counting links: the more links lead to a page, the more popular a page is. Moreover, a search engine can apply different Machine Learning algorithms such as LambdaMART or RankSVM to additionally improve the result.
After following these steps, we have a structured and truly relevant set of pages that, with a high probability, can satisfy most users.
Is your Search Engine a good one?
The first question we need to ask is: what makes a search engine a “good” search engine? The most commonly accepted answer is relevance. If the results of a search are pertinent to the query, the search engine did a good job.
The second question is: who decides if results are relevant? Ideally, the best way to measure pertinence is human judgement, but it can be very slow and expensive. So the solution of choice is typically an automatised Search Quality Evaluation Tool like RRE or trec_eval.

Another thing you must consider when building a search engine is spam. The internet, as you may know, is really competitive and, for this reason, a lot of pages are manipulated to achieve high rankings. This practice, known as Search Engine Optimisation, is essential for new sites but is also usually abused by spammers. To contrast this behaviour, it is advisable to use machine learning classifiers and to design more complex ranking solutions.
So now that you have an idea of how a search engine works, you can download one of many Open Source Search Engines and start experimenting. And if you need inspiration, go take a look at PISA, created by Antonio Mallia.



