
Artificial intelligence (AI) and machine learning (ML) increasingly seem to be indispensable tools that developers need to be able to handle. There are many ways these tools can be put to use, applied to applications and products. In research and academia, the subject has been around for 70 years or so – more or less the same time span which separates the birth of computers and information technology from the present day. However the popularity of this field has fluctuated considerably in the last few decades, experiencing dark times (the infamous ‘AI Winter’) and golden eras, such as the present (a phase that does not seem destined to end any time soon).
Why you may need artificial intelligence?
The immediate impact on everyday lives of Artificial Intelligence and similar technologies has never been as popular and widely (if not wildly) acknowledged as in the present day. Every CEO wants their company to use it, produce it, develop it – and every developer wants to join the party. Of course, there is nothing wrong with that: on the contrary, for an entrepreneur it is a natural impulse to exploit state of the art technologies in order to keep pace with competitors and to try to take a forward step before them. It is also perfectly natural for a developer to be intrigued, at the very least, by an impressive and pervasive technology that, although still rather intricate from the theoretical point of view, is largely accessible in terms of both tools and programming systems.

Even if you don’t want to learn Python, R or Scala (though you should!) and prefer to stick to the Java and C# you probably use in your daily work, ready to use libraries and frameworks will be found within your favourite computer language. If readers will permit a personal digression, my first experiences with AI were in BASIC(!) and my first professional project in the field (being paid to deliver an AI product) some twenty years ago was in C: at the time I had to do most of the work ‘by hand’, due to a lack of standardised libraries (or indeed any libraries at all) suited to my purpose.
Today, things are simpler for developers in this respect: one can learn a library or framework for an already-familiar language, or learn the foundations of an easier interactive language, such as Python or R, and start using de facto the standard libraries such as TensorFlow that are available for many mainstream languages (even for Javascript).
In short, it is a natural and healthy instinct for a developer to be interested in participating in and delivering AI projects. The easiest introduction involves finding tutorials, explanations, or introductions written by other developers, and downloading open source tools. Such tools (Jupyter notebooks, for example) are usually easy to install and easy to use for those who are just starting to code and to solve problems using AI methods.
Of course, where both CEOs and developers (whose salaries are paid by CEOs) want to work with AI, it is obvious that the team’s joint efforts will result in the delivery of AI products or solutions to sell to customers.
However, it is precisely at this point that things become difficult: while a single developer may create a Jupyter notebook that brilliantly solves some regression, prediction or generation problem, to transform that solitary effort into a standard delivery pipeline is very difficult – often, it may be better to restart from scratch.
On the one hand, projects – collective efforts performed by teams – are what leads to delivery; on the other hand, an enterprising solution needs to satisfy business requirements – the first goal of any profitable project. In other words, first the business case, next the technology required to efficiently satisfy that need.
Developers playing with Pytorch late at night may produce interesting prototypes, which may suggest ways to solve a problem or need experienced by the company but creating a new product on the strength of that idea alone is another matter entirely. A production pipeline with delivery of an AI-based product, made for a specific purpose as its goal is needed, and will need to be managed properly. Artificial Intelligence project management is another interesting issue but will be dealt with elsewhere.
What is Google AI Hub?
The time has now come to introduce our main character, Google AI Hub: at first glance, this is just a repository of tools able to provide the individual parts of the pipeline mentioned above. It is also an ecosystem of plugins and goes as far as supplying end-to-end pipelines to support the delivery of an AI product, at different levels of abstractions, according to the resources available to produce it.
In fact, AI Hub is more than a repository, providing different assets for different goals: for example, it can be used to learn ML algorithms, or to use built artefacts available either in the public domain via Google, or shared as plug-ins within your organisation. Alternatively, one can use AI Hub to share one’s own models, code and more with peers in the same organisation – a hub that facilitates collaboration on AI projects by means of reuse, sharing and factoring.Let’s begin by finding something useful just to play with – something ready to use. Visit the site homepage on which assets are classified in categories in a menu of the left hand side. Choose the ‘Notebook’ category for this example:
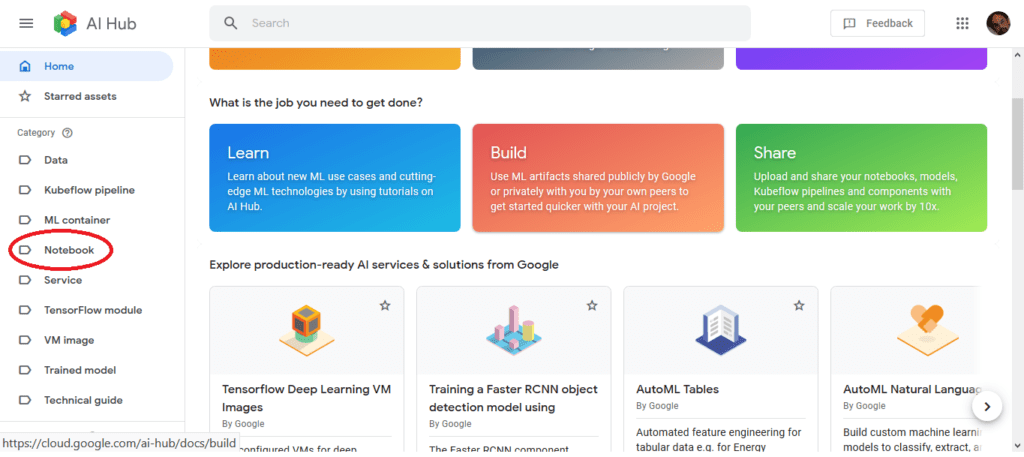
This offers a list of notebooks provided by Google. For our current purposes, we could open the first and start using it.
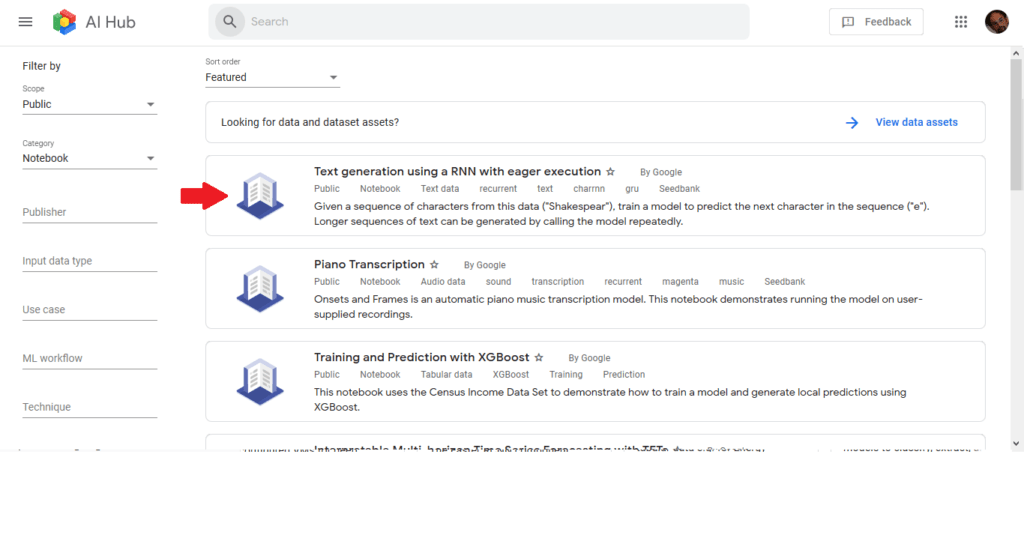
Once we access the asset – in this case a Notebook – we can open it in Colab to explore and exploit. This is a simple asset exploitation of course, but Google-provided notebooks are great; well documented and easy to use, they’re a good way to learn by doing.
Among the available assets we find datasets, services (API, for example, which may be called on by your application to use built-in functionalities, or to train your model via transfer learning, etc.), trained models, TensorFlow modules, virtual machine images, and Kubeflow pipelines. All these assets occur somewhere in the development process of an AI application. The importance of Kubeflow pipelines – an interesting way to embed AI models inside an application – should be particularly stressed, but more on that later.
How to benefit from Google AI Hub
In this introductory note we cannot give a general overview of all the tools available on the Google AI Hub dashboard (the platform itself provides several tutorials on how to start using each tool and resource it makes available). In place of this, we offer some hints on the task of deploying a scalable ML application through the hub.
An important initial note about using AI Hub for practice is that you will need a Google Cloud Platform account. Starter accounts that are essentially free of charge are available, but you’ll need to provide bank account details. It’s probably best to operate inside an organisation account instead – typically one belonging to your company: organisations have the ability to use and share assets via the Hub. For example, if you work in R&D you can share prototypes with your colleagues working on architecture, delivery or another aspect of the product.
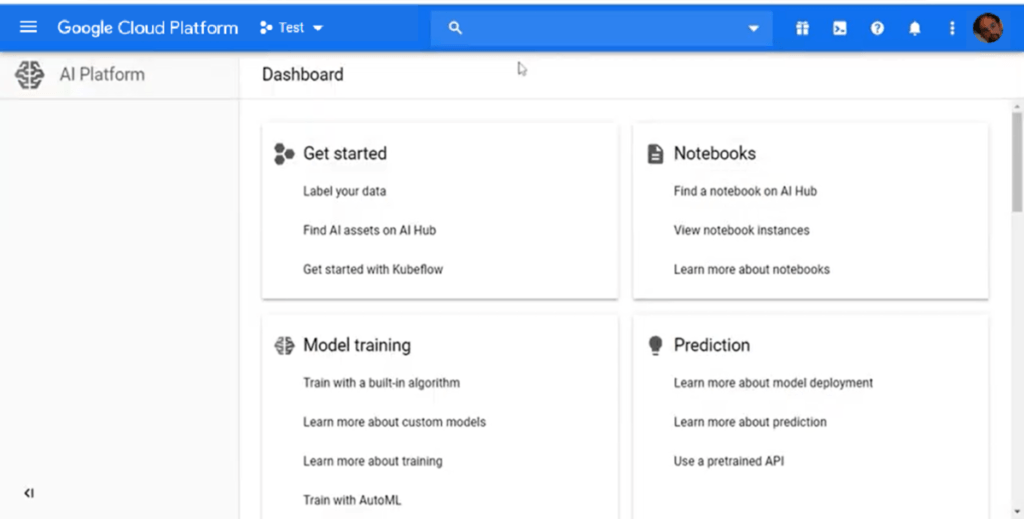
The dashboard of the platform allows management of projects using assets from the hub. A project may start as a simple Jupyter notebook, for which you can choose not only the language (Python 2/3, R, …) but also the computational sizing (e.g. if you need some kind of GPU to properly run it, etc.) and other parameters. All of these factors determine the cost of the service needed to run the notebook.
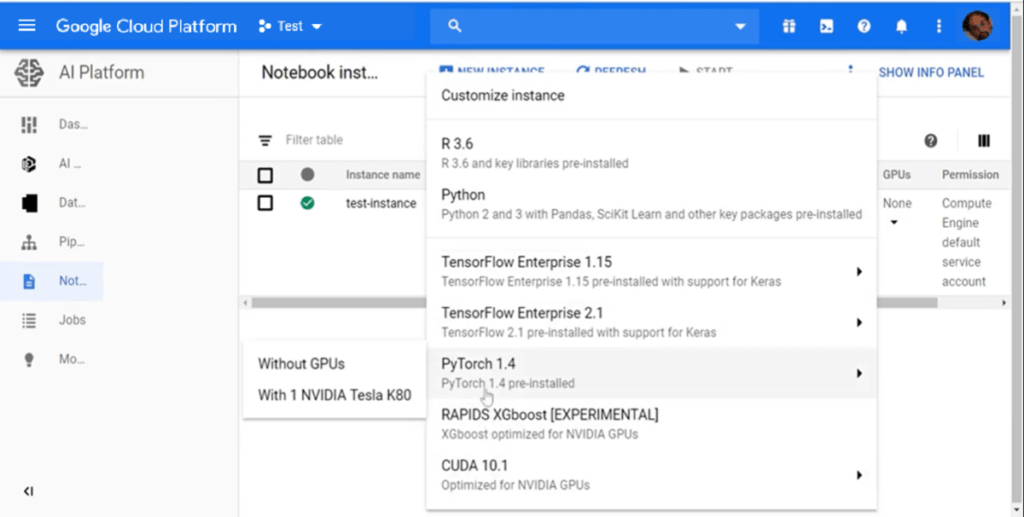
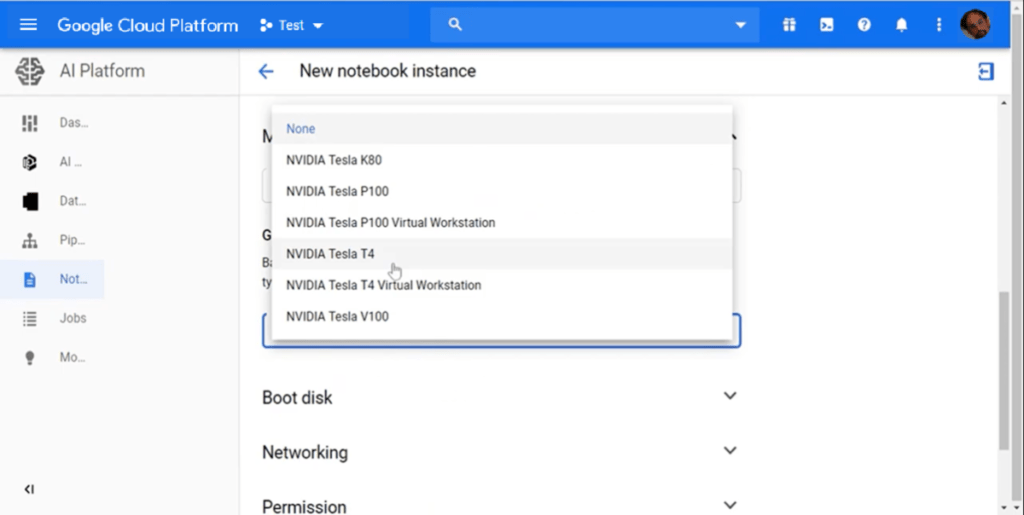
Needless to say, you can edit and run your notebook on the cloud platform as you would in your local environment: you’ll find all the main tools already available for whichever language and framework you chose; for example, TensorFlow is already installed in the Python environments, and you can ‘Pip’ whatever additional packages you need.
It is also easy to pull and push your notebooks from and to Git repositories, or to containerize your notebook in order to install specific libraries and acquire the level of customization your code requires to run properly.
At a certain point (probably at the start!) you’ll need to handle a dataset, perhaps to train your model or to fine tune a pre-trained model. AI Hub provides a section on datasets that is not simply a bookmark or repository but allows for labelling data. This is a practical need in many projects, and the lack of a dataset appropriate for your supervised model is a frequent issue when trying to build a product based on ML models.
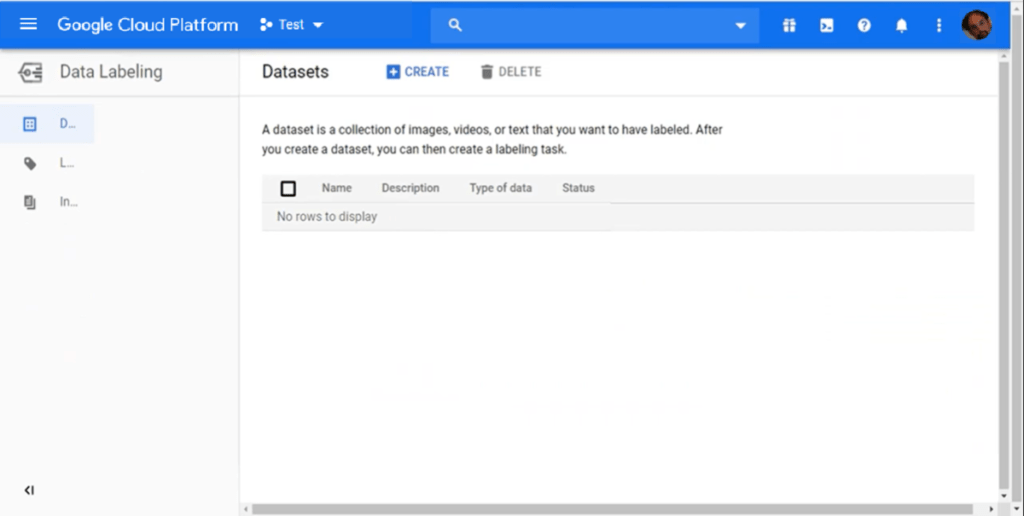
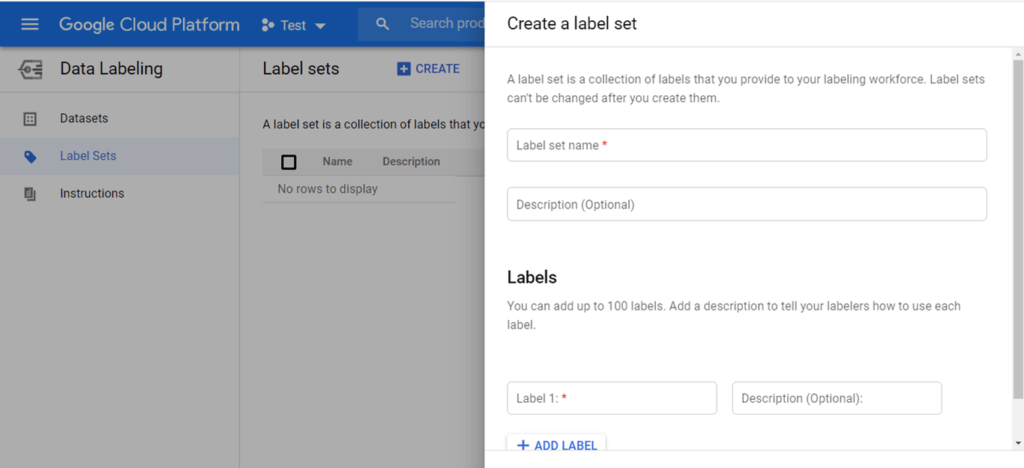
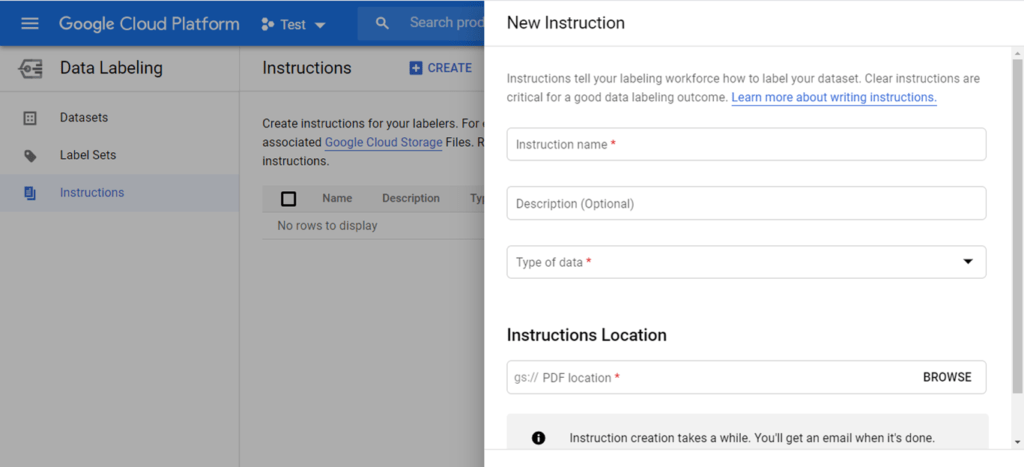
In this section of the hub you can add a dataset for which you can specify the kind of data and its source, upload data and specify a label set which provides the complete list (to the best of your knowledge) of labels of your data. This is not only for recording purposes: in fact you can also add a set of instructions and rules according to which human labellers may attach labels to the elements of your dataset. This feature allows you to specify the requirements of a labelling activity to be performed by someone paid to do it on your behalf.
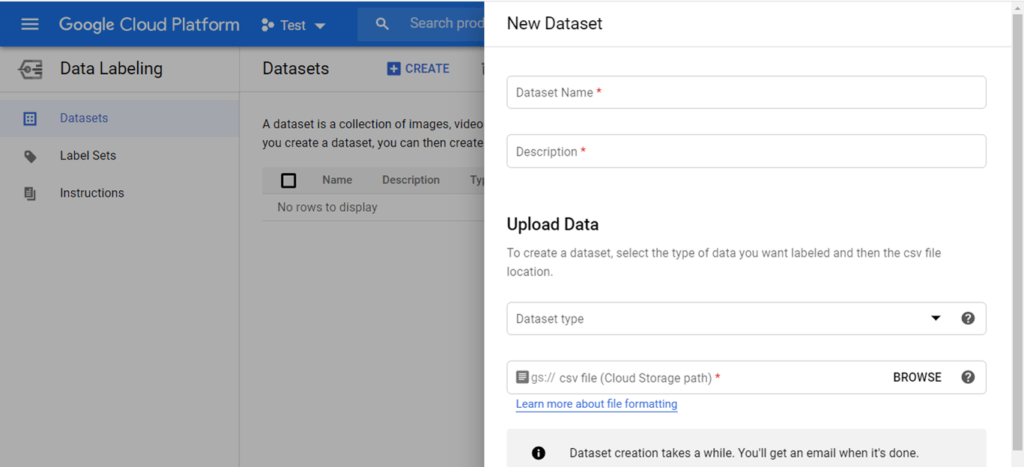
However, labelling data is not an easy task and is subject to ambiguities (people do this task instead of a machine for some very good reasons!) so one may need to refine instructions and initially provide a limited trial dataset on which to assess both the quality of labelling and the level of description actually required in the instructions. Since this is a crucial step in training a ML model, real life projects will require people to manage this activity by collaborating closely with the developers to get a useful, and as unbiased as possible, dataset on which to train the ML model.
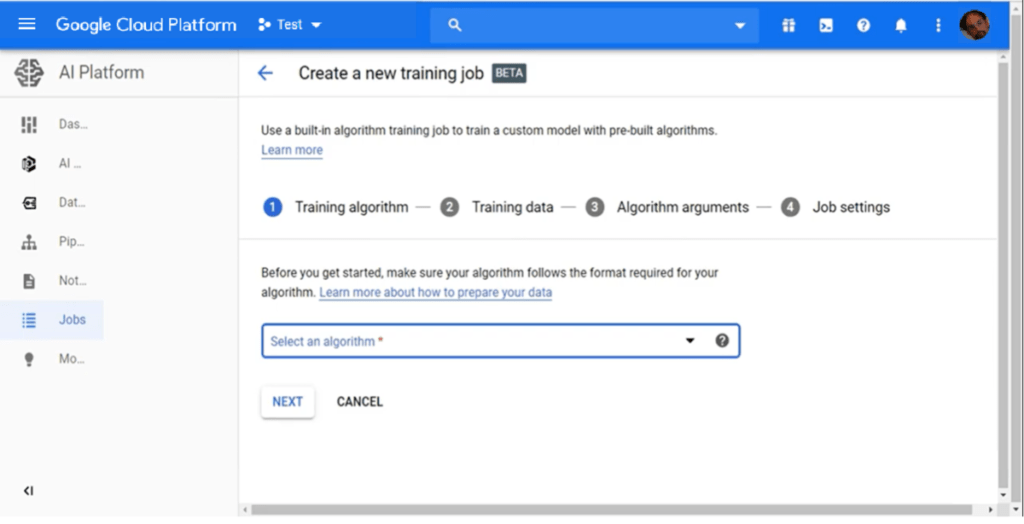
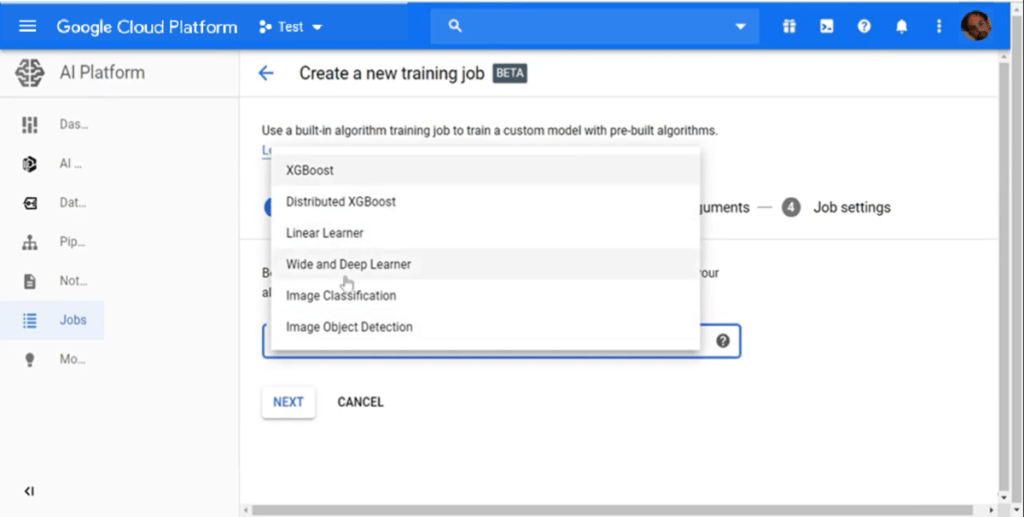
‘Jobs’ is another interesting feature from the AI platform. Used to train models, you may define these using standard built-in algorithms or your own algorithm, according to your model’s needs. In most cases algorithms built in the platform will suffice for training purposes.
Up to this point we have talked about models, datasets (and the interesting labelling feature) and training jobs: these tasks form the bulk of an AI developer’s day-to-day work, whether on their local systems or on the shared tools provided by their organisations.
A complete, end-to-end ML pipeline is somewhat more complicated, however, requiring at least the following steps
- Data ingestion to encapsulate data sourcing and persistence: this should be an independent process for each dataset needed, and is a typical job;
- Data preparation: to extract, transform and select features which increase efficiency and should not deteriorate performances;
- Data segregation, to split datasets into the parts needed for different purposes, for example: training set and validation set, as required by different validation strategies.
- Model training on training datasets, which may be parallelized using either datasets or models (most applications put different models to work).
- Model assessment on validation datasets, when performance measurements are also taken.
- Model deployment: the model could be programmed in a framework which is not the native framework of the application (e.g. R for modelling, C# for production code) so that deployment may demand containerization, service exposition, wrapping, etc.
- Model use in the production environment with new data.
- Model maintenance – mostly performance measurement and monitoring, to correct and recalibrate the model if needed.
In this ‘model lifecycle’, the final step, i.e., the integration with the application which needs the model, is typically not covered by AI frameworks and hence is the most problematic step for a developer team, yet the most important step for the business.
The ecosystem which AI Hub embraces to achieve these results is based on Kubeflow (in turn based on Kubernetes), which is essentially used as the infrastructure for deploying containerized models in different clusters, and as the basic tool to access scalable solutions.
A possible lifecycle could be as follows (for more information on this specific tool check this link).
- Set up the system in a development environment, for example on premises e.g., on your laptop.
- Use the same tools that work for large cloud infrastructures in the development environment, particularly in designs based on decoupled microservices etc.
- Deploy the same solution to a production environment (on premises or cloud cluster) and scale it according to real need.
Kubeflow began as the way Google ran Tensorflow internally, using a specific pipeline designed to let TensorFlow jobs run on Kubernetes.
A final word on sharing: as we have said, all these tasks cannot be accomplished by a single developer alone, unless they are experimenting by themselves: in production environments a team of developers, analysts and architects usually cooperate to deliver the project. Developers in particular cooperate, and sharing is an essential part of cooperation.
Assets uploaded or configured on AI Hub can be shared in different ways:
- simply add a colleague by using their email address, much as in other Google tools when sharing documents, etc.
- share with a Google group
- share with the entire organisation to which one belongs.
Moreover, different profiles may be assigned to people we are sharing with, essentially a read only profile and an edit profile.
All in all, although it is not always easy to use and is subject to several constraints, Google AI Hub is a complex tool which may be used to deploy and scale ML applications or ML models to integrate into business applications, within a uniform framework. It is difficult to say if this will become the standard of ML deployment but it certainly traces a roadmap toward a flexible engineering of the ML model lifecycle.


