
Benvenuti a OpenDev Explorer, la mia rubrica dedicata all’esplorazione del mondo Open Source che strizza un occhio alla developer experience. Io sono Riccardo (aka TheZal) e oggi vi parlerò del super database più veloce nel mondo delle time-series: QuestDB!
Panoramica generale

Oggi facciamo la conoscenza di QuestDB: un database time-series open source che promette di essere più veloce di Flash. Creato da Vlad Ilyushchenko, si propone come un database time-series che può essere utilizzato per analizzare grandi quantità di dati in tempo reale. QuestDB è stato creato per essere veloce e scalabile e può essere utilizzato per analizzare dati in tempo reale provenienti da sensori, log, metriche e dati di qualsiasi provenienza, purché siano time-series.
Manuale di istruzioni
Installazione
Iniziare ad utilizzare QuestDB è molto semplice, grazie alla sua immagine Docker ufficiale. Per iniziare a giocare con QuestDB basta eseguire il seguente comando:
docker run \
-p 9000:9000 -p 9009:9009 -p 8812:8812 -p 9003:9003 \
questdb/questdb:7.3.9Questo comando eseguirà l’immagine Docker ufficiale di QuestDB e la esporrà alle porte 9000, 9009, 8812 e 9003. Una volta eseguito il comando, sarà possibile accedere all’interfaccia web di QuestDB all’indirizzo http://localhost:9000 e iniziare ad utilizzare il database.
Utilizzo
Come detto sopra all’indirizzo http://localhost:9000 sarà possibile accedere all’interfaccia web di QuestDB. Questa interfaccia è molto intuitiva e permette di creare tabelle, inserire dati, eseguire query e visualizzare i risultati in maniera molto semplice e veloce.
Inoltre QuestDB espone una REST API sempre alla porta 9000 con cui è possibile eseguire delle query, una porta 8812 che espone un protocollo per la comunicazione basato su PostgreSQL e una porta 9009 che espone un protocollo per la comunicazione basato su InfluxDB.
L’utilizzo quindi di QuestDB tramite applicativi è tutt’altro che complicata, i suoi protocolli permettono quindi di interagire con il database out of the box.
La developer experience
La developer experience di QuestDB è uno dei suoi punti forti grazie alla documentazione molto chiara e ben fatta e al fatto che permette di iniziare ad utilizzare il database in pochi minuti. Inoltre, la community è molto attiva e risponde in maniera molto rapida alle domande poste su GitHub o su Slack.
Un altro punto a favore della developer experience di QuestDB è rappresentata dalla perfetta integrazione con Grafana, che permette di visualizzare i dati presenti in QuestDB con poco sforzo.
L’extra mile
La caratteristica distintiva di QuestDB è rappresentata dalla possibilità di utilizzare il linguaggio SQL per eseguire le query, cosa che rende l’utilizzo di QuestDB molto semplice per chiunque abbia già esperienza con SQL. Secondo me è questa la caratteristica che corrisponde all’extra mile del progetto stesso.
Inoltre integra anche diverse SQL extensions fondamentali per l’analisi dei dati time-series, come ad esempio la timestamp search e le windows function.
Articolo consigliato: Bruno, un bassotto a caccia di API
Il confronto con lo status quo
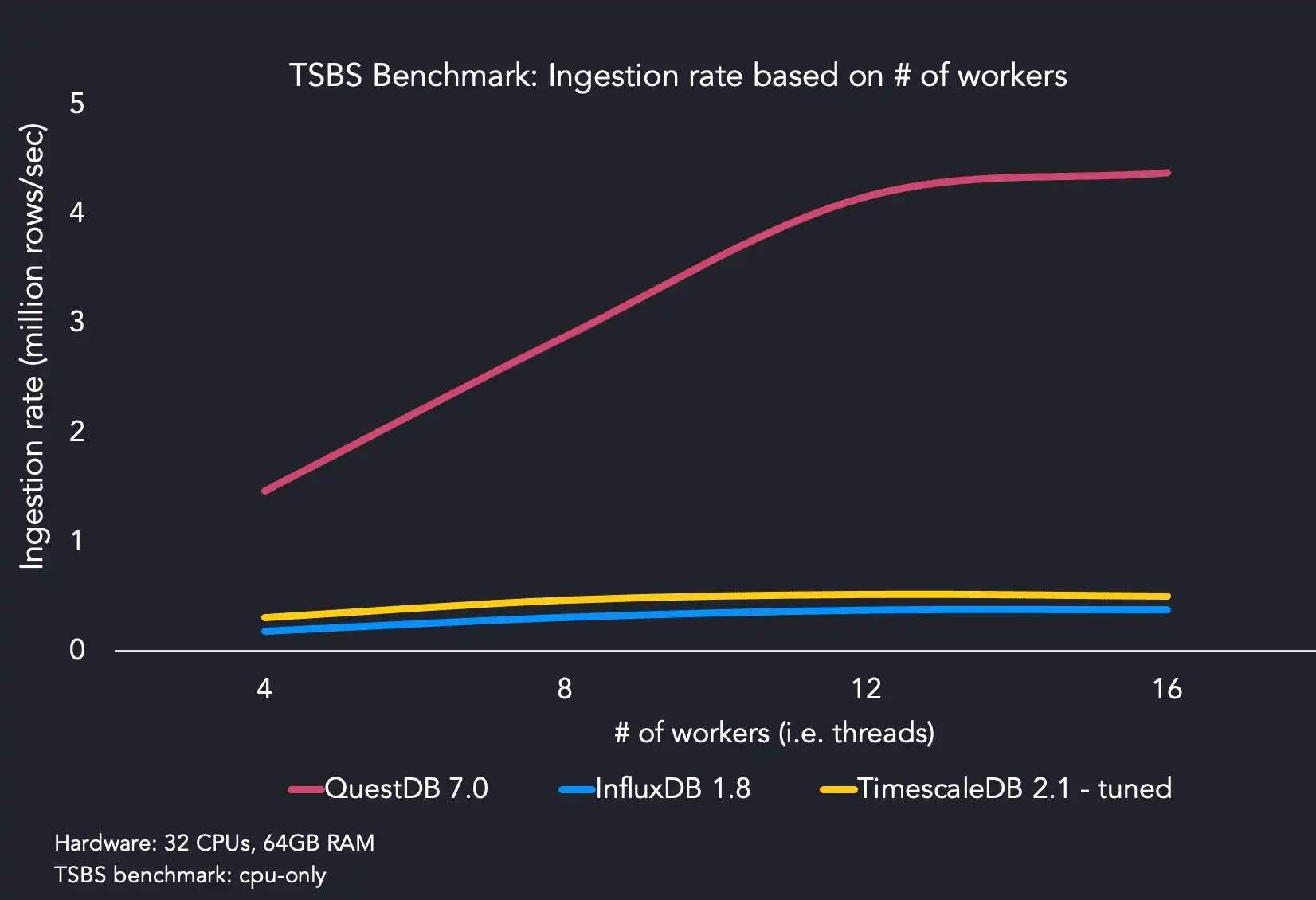
Il database di riferimento per l’analisi di dati time-series è InfluxDB, ma QuestDB raggiunge prestazioni migliori e permette di eseguire query in maniera molto più veloce. Inoltre, InfluxDB non permette di utilizzare il linguaggio SQL per eseguire le query, cosa che rende l’utilizzo di QuestDB molto più semplice per chiunque abbia già esperienza con SQL.
Tiriamo le somme!
Non nascondo che sono rimasto molto colpito da QuestDB, sia per le sue prestazioni che per la sua semplicità d’uso. Ad oggi è diventato il mio database di riferimento per l’analisi di dati time-series ed è diventata la prima scelta (dopo averlo confrontato con TimescaleDB e InfluxDB) nei deploy di progetti che hanno la necessità di un database prestazionale specializzato. Lo consiglio a chiunque abbia bisogno di analizzare grandi quantità di dati in tempo reale.
Darete una chance a QuestDB? Qui è TheZal che vi saluta e vi aspetta al prossimo episodio di OpenDev Explorer!
