
Quando si parla di analisi dei dati, Pandas è sicuramente la libreria Python più potente e ampiamente utilizzata per la manipolazione, la pulizia e l’elaborazione dei dati. Grazie alle sue funzionalità, infatti, possiamo lavorare con dati tabulari, recuperandoli da database SQL o fogli di calcolo di Excel, ad esempio.
Pandas ci dà anche la possibilità di manipolare e pulire i dati per prepararli per analisigrafiche, ma anche per il Machine Learning. In questo articolo, introdurremo Pandas e il concetto di data frame in Pandas. Successivamente, mostreremo alcune delle caratteristiche di Pandas con esempi pratici di analisi dei dati.

Introduzione a Pandas
Che cos’è Pandas?
Questo è ciò che gli sviluppatori dicono sul sito web di Pandas riguardo alla loro missione:
“pandas aims to be the fundamental high-level building block for doing practical, real-world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis/manipulation tool available in any language”.
Quindi, stiamo parlando di ciò che punta ad essere l’unica libreria che ci verrà in mente quando pensiamo alla parola “analisi dei dati”.
E, ad essere sinceri, è davvero così: quando parliamo di librarie di analisi dei dati con chi lavora nel settore, la prima cosa che possa veramente venire in mente a chiunque è Pandas.
Come installare Pandas
Ci sono un paio di modi per installare Pandas sul tuo computer:
Se hai già Python installato, puoi installare Pandas col classico metodo:
$ pip install pandas
L’altro modo, invece, prevede di installare Anaconda sul tuo computer. Questo è il mio metodo preferito perché installerà Python, Pandas, tutte le librerie legate alla Data Science e al Machine Learning, e molte altre ancora.
Quindi, installando Anaconda, praticamente non avrai bisogno di installare altre librerie Python in futuro. Per scoprire come installarlo sul tuo computer, puoi consultare il loro sito web.
Definizione delle Pandas series e dei data frame in Pandas
Un data frame è una tabella, simile a un foglio di calcolo, in cui possiamo organizzare ed analizzare dati ed informazioni.
In altre parole, possiamo pensare ad un frame dati come a un contenitore che mantiene e organizza i dati in colonne e righe, come segue:
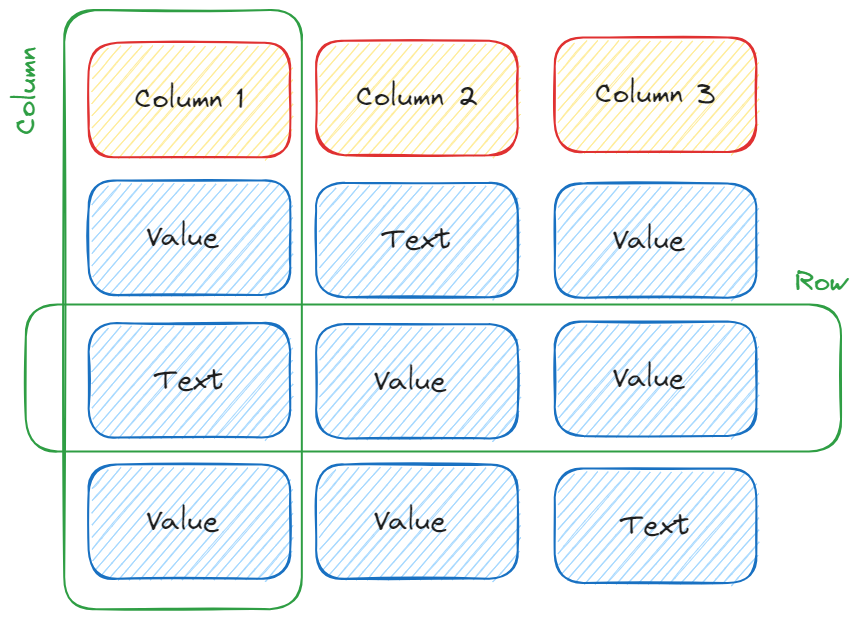
Quindi, un data frame è un contenitore ordinato di dati, i quali possono essere collezionati sotto forma di testo o numeri, e sono organizzati in colonne e righe.
In particolare, ogni colonna di Pandas viene anche chiamata “Pandas series”. Quindi, un altro modo per vedere un data frame in Pandas è questo: un data frame è una raccolta ordinata di Pandas series.
Creazione e visualizzazione di un data frame in Pandas
Per lavorare con i dati tabulari abbiamo due possibilità:
- I dati sono stati creati da qualche parte e sono memorizzati in un file. Possiamo aprire il file in Pandas e utilizzare i dati al suo interno.
- Possiamo creare un data frame tramite codice e utilizzarlo immediatamente.
Qui di seguiro mostreremo la seconda opzione, mentre la prima sarà illustrata nel paragrafo successivo.
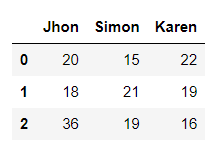
In Pandas, possiamo creare un data frame con la stessa sintassi con cui creeremmo un dizionario in Python. Quindi, supponiamo di voler creare un data frame che raccolga i valori relativi ai tempi misurati, in secondi, di alcune persone che hanno effettuato vari tentativi di corsa. Possiamo farlo nel seguente modo:
import pandas as pd
# Create data frame
times = pd.DataFrame({"Jhon":[20, 18, 36], "Simon":[15, 21, 19], "Karen":[22, 19, 16]})
# Show first 10 values
times.head()Code language: PHP (php)Quindi, importiamo Pandas come “pd” in primo luogo. Successivamente, creiamo un data frame con il metodo pd.DataFrame(). Infine, utilizziamo il metodo head() per mostrare i primi 5 valori del nostro data frame.
Il risultato è il seguente:
Ora, andiamo ad utilizzare dai dati veri per poter vedere alcune features di Pandas.
Manipolazione dei dati in Pandas: un tutorial pratico con dati reali
Il modo migliore per imparare Pandas è prendere dei dati e iniziare a programmare. Questo perché è una libreria talmente vasta che studiare e capire la teoria è del tutto inutile. La cosa migliore da fare è iniziare subito a sporcarsi le mani coi dati.
Per mostrare alcune delle caratteristiche di Pandas, abbiamo preso alcuni dati relativi alla popolazione mondiale (il file è scaricabile da Kaggle qui) per analizzarli.
Come possiamo vedere, i dati sono in formato CSV, che è uno dei formati più tipici coi cui ci troviamo a lavorare. Supponendo di aver rinominato il file “population.csv”, ecco come possiamo aprirlo e vedere i primi cinque valori per ogni colonna:
import pandas as pd
# Read CSV
population = pd.read_csv("population.csv")
# Show head
population.head()Code language: PHP (php)E otteniamo:
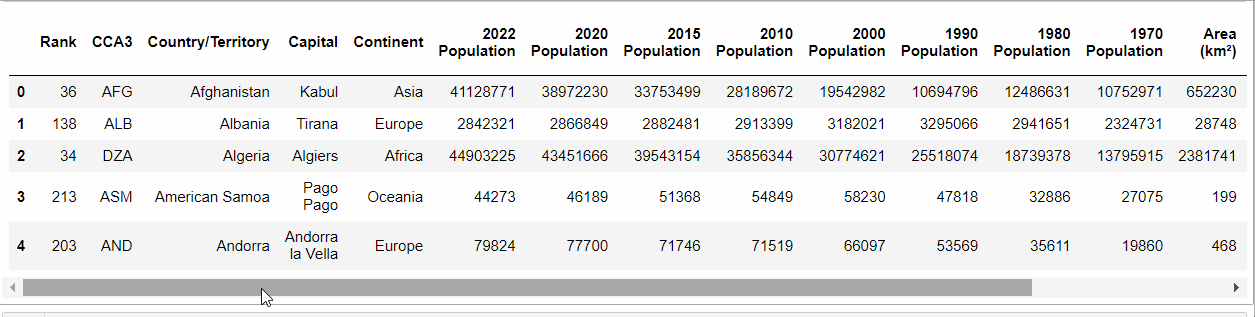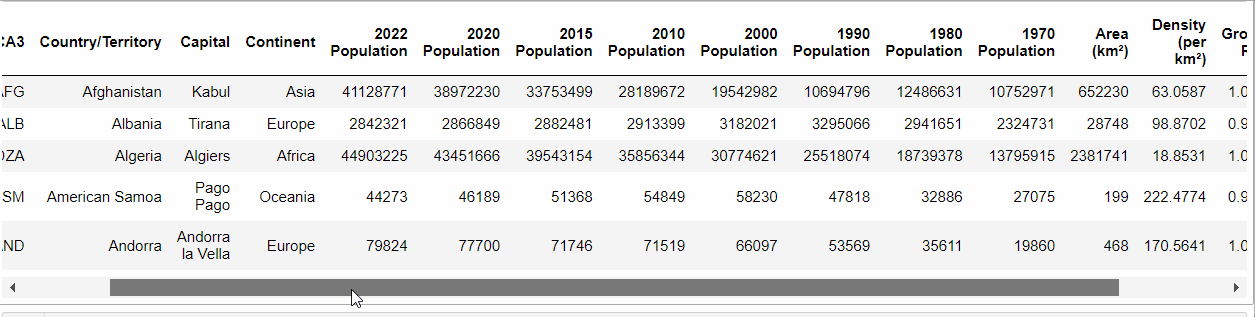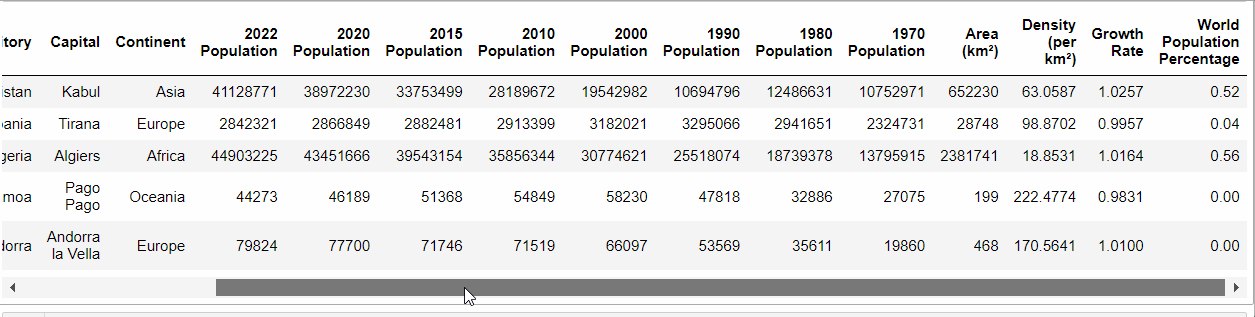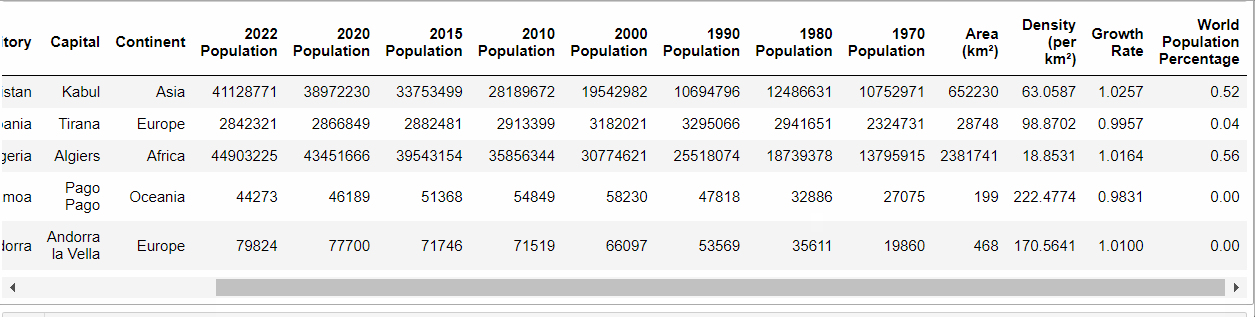
Quindi, abbiamo un data frame con “molte” colonne. Ma quante colonne ha? E quante righe?
Per vedere questi valori e rispondere alla domanda, possiamo digitare il codice che segue:
# Show shape
population.shape
>>>
(234, 17)Code language: CSS (css)Quindi, il nostro data frame ha 234 righe e 17 colonne.
Una delle cose importanti da fare quando si analizzano i dati e verificare se il nostro data frame contenga o meno dei valori nulli.
Lo si può fare così:
# Show Null values
population.isnull().sum()
>>>
Rank 0
CCA3 0
Country/Territory 0
Capital 0
Continent 0
2022 Population 0
2020 Population 0
2015 Population 0
2010 Population 0
2000 Population 0
1990 Population 0
1980 Population 0
1970 Population 0
Area (km²) 0
Density (per km²) 0
Growth Rate 0
World Population Percentage 0
dtype: int64Code language: PHP (php)E il risultato ci mostra che non ci sono valori nulli nelle varie colonne. Quindi, possiamo procedere con la nostra analisi senza preoccuparci dei valori nulli.
Ora, supponiamo di non essere interessati a tutte le colonne del data frame perché riteniamo che alcune di esse forniscano dati che non ci interessano. Possiamo creare un altro data frame che contenga solo le colonne che vogliamo analizzare.
Ad esempio, supponiamo di non essere interessati alle seguenti colonne: “Rank” e “CCA3”. Possiamo decidere di creare un altro frame dati senza queste due colonne digitando quanto segue:
population = population.drop([“Rank”, “CCA3”], axis=1)Quindi, con il metodo drop(), eliminiamo le colonne che non ci interessano, ma dobbiamo specificare l’asse. In Pandas, axis=1 rappresenta la direzione verticale, mentre axis=0 rappresenta la direzione orizzontale (e quindi la si utilizza quando vogliamo eliminare delle righe).
Inoltre, non ci piace molto il fatto che una colonna si chiami “Country/Territory” perché se dobbiamo creare un filtro per questa colonna dovremmo specificare il nome intero, con elevato rischio di errori. E’, quindi, meglio rinominarla. Per rinominare una colonna si può fare così:
population = population.rename(columns={"Country/Territory":"Country"})Code language: JavaScript (javascript)Supponiamo ora di voler tracciare l’andamento della popolazione nel tempo, in relazione ai primi tre paesi asiatici per tasso di crescita. In altre parole: vogliamo intercettare i primi tre paesi asiatici per tasso di crescita nel tempo e vogliamo tracciare l’andamento della popolazione nel tempo.
Possiamo farlo in questo modo:
import matplotlib.pyplot as plt
# Select Asian Countries and create a new data frame with them
asia = population[population["Continent"] == "Asia"]
# Order data frame for growth rate
asia_sorted = asia.sort_values(by="Growth Rate", ascending=False)
# Select the top 3 Countries for growth rate
top_3_countries = asia_sorted.head(3)
# Select the columns with "Population"
population_columns = [col for col in population.columns if col.endswith("Population")]
asia_population_df = asia[population_columns]
# Order columns from 1970 to 2022
asia_population_df = asia_population_df.iloc[:, ::-1]
# Transpose the columns
asia_population_df = asia_population_df.transpose()
# Select the Country in Asia
asia_population_df.columns = asia["Country"]
# Create plot
# Select the top 3 Countries per growth rate in Asia
top_3_population_df = asia_population_df[top_3_countries["Country"]]
top_3_population_df.plot(figsize=(10, 6))
# Label title and axes
plt.title("Population in Asia with the max growth rate")
plt.xlabel("Year")
plt.ylabel("Population")
# Show legend
plt.legend(loc="upper left")
# Rotate x-axis values
plt.xticks(rotation = 'vertical')
# Show plot
plt.show()Code language: PHP (php)E otteniamo:
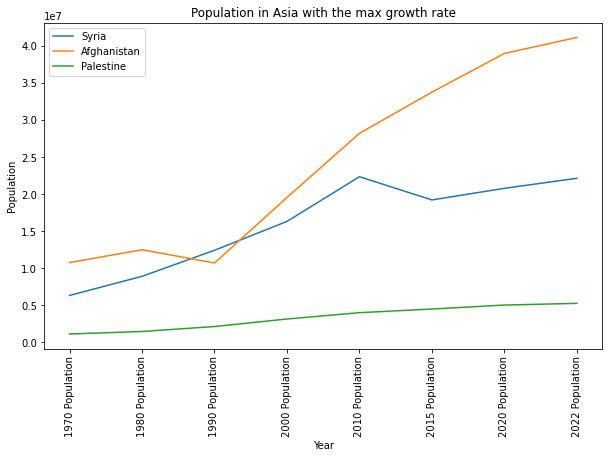
Nel codice sopra abbiamo:
- Selezionato “Asia” nella colonna “Country” tramite il codice: population[population[“Continent”] == “Asia”]
- Ordinato il data frame col metodo sort_values(), scegliendo “Growth Rate”. Abbiamo poi selezionato i primi tre risultati col metodo head(3).
- Preso tutte le colonne il cui nome finisce per “Population”, col metodo endswith(), e abbiamo creato un altro data frame chiamato asia_population_df.
- Ordinato in modo temporale (dal 1970 al 2022) il data frame col metodo iloc().
- Trasposto le colonne col metodo transpose(). Questo significa che le colonne che contengono i dati di popolazione per ogni anno adesso sono delle righe: in questo modo possono essere rappresentte sull’asse orizzontale del grafico.
- Selezionato “Asia” con asia[“Country”], per fare il grafico
- Selezionato le prime tre [top_3_countries[“Country”], per fare il grafico.
- Usato Matplotlibper fare il grafico dei dati.
Supponiamo ora di voler mostrare l’andamento della popolazione negli anni relativo ai 5 Paesi con il valore massimo di “World Population Percentage”. Possiamo farlo in questo modo:
import matplotlib.pyplot as plt
# Sort for pop. percentage
population = population.sort_values(by="World Population Percentage", ascending=False)
# Top 5
top_5_countries = population.head(5)
filtered_df = population[population["Country"].isin(top_5_countries["Country"])]
# Select the column with population values
population_columns = [col for col in filtered_df.columns if col.endswith("Population")]
population_df = filtered_df[population_columns]
# Order columns from 1970 to 2022
population_df = population_df.iloc[:, ::-1]
# Traspose the columns
population_df = population_df.transpose()
# Filter for Country
population_df.columns = filtered_df["Country"]
# Plot
population_df.plot.line(figsize=(10, 6))
plt.title("Population trend over the years: top 5 Countries per World Population Percentage")
plt.xlabel("Year")
plt.ylabel("Population")
# Rotate x-axis values
plt.xticks(rotation = 'vertical')
# Show legend
plt.legend(loc="upper left")
# Show plot
plt.show()Code language: PHP (php)E otteniamo:
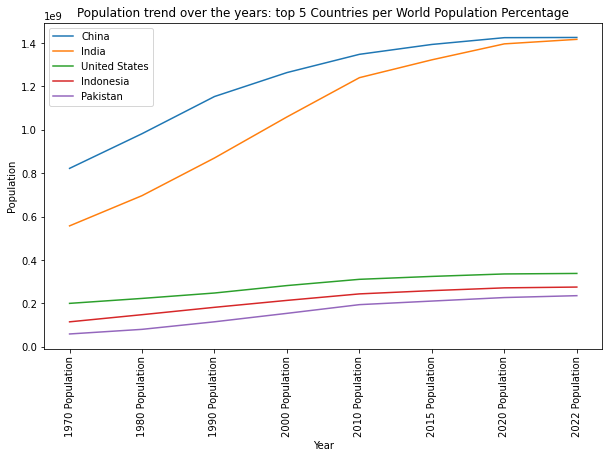
Il codice è abbastanza simile al precedente.
L’unica differenza è che qui non abbiamo filtrato per Paese: abbiamo selezionato i primi 5 Paesi al mondo per percentuale di popolazione e abbiamo tracciato l’andamento della popolazione nel corso degli anni.
Questo grafico, in particolare, mostra come la popolazione in Cina e in India stia crescendo velocemente nel corso degli anni.
Conclusioni
In questo articolo, abbiamo visto come possiamo utilizzare Pandas per manipolare i dati al fine di ottenere informazioni da essi, mediante la creazione di grafici specifici.
Il modo migliore per imparare Pandas è ottenere dei dati di nostro interesse e esplorarli, grazie alla curiosità ed all’interesse che abbiamo per essi. In questo modo, si impara Pandas con un approccio pratico, che è l’unico modo che ti aiuterà a impararlo in modo efficace.
